Conjunto de elementos que tem, pelo menos, uma característica em comum.
Subconjunto da população, parte da população.
É representativa da população, sendo válidos os resultados obtidos, por meio do uso da inferência estatística.
 TEMA DE APRENDIZAGEM
TEMA DE APRENDIZAGEM
Correlação Regressão Linear E Inferência Estatística
Ao iniciar a leitura deste material, você pode já se perguntar: porque estudar correlação e regressão linear? Terei que fazer estimações de y a partir de x conhecido? Para que fazer um teste de hipóteses? Quando você estuda um comportamento conhecido e pode fazer estimações ou testar uma amostra, estará, certamente, utilizando uma técnica importante que será trabalhada aqui em Bioestatística.
A correlação e a regressão linear ajudarão você a mensurar a força da relação entre X e Y, e a reta de regressão linear, você poderá fazer estimativas para Y a partir de X conhecido e, com isso, poderá trabalhar dentro de um modelo matemático conhecido, que ajudará em sua pesquisa. Já a inferência estatística trata-se de um conjunto de técnicas que tem por objetivo principal analisar uma população, por meio de evidências de uma amostra, para isso, temos: teste de hipóteses e intervalo de confiança, que estudaremos. O vídeo estará disponível no seu ambiente virtual de aprendizagem.
Assim, convido você a fazer um levantamento de artigos, reportagens, que tragam situações envolvendo correlação linear, regressão linear e inferência estatística. Faça um compilado e comece a identificar que os testes de hipóteses poderão ajudá-lo na tomada de decisões.
Agora, avaliaremos se há uma associação entre duas variáveis com características quantitativas, que é objetivo de inúmeros estudos em ciências biológicas e/ou da saúde. Por exemplo: um biomédico pode ter interesse se há relação entre a quantidade de chumbo em medida na água e no volume de efluentes despejados em certo rio; um profissional da área da saúde pode querer saber se existe relação entre a pressão arterial e idade das pessoas; um professor pode querer saber a relação entre peso e altura, e assim por diante.
Quando existe a necessidade de analisar a relação entre essas duas variáveis, chamamos de correlação.
Vejamos um exemplo: um professor de enfermagem deseja saber se existe correlação entre o tempo dedicado ao estudo e o desempenho dos alunos na disciplina Bioestatística. Assim, ele selecionou oito alunos, assim, podemos observar o número de horas (x) e nota obtida na prova de Bioestatística (y) para cada aluno(a).
Tabela 1 - Relação entre as horas de estudo e nota na disciplina de Bioestatística
|
Acadêmico |
Horas de Estudo (x) |
Nota em Bioestatística (y) |
|---|---|---|
|
A |
8 |
10 |
|
B |
8 |
8 |
|
C |
6 |
4 |
|
D |
5 |
8 |
|
E |
4 |
6 |
|
F |
7 |
9 |
|
G |
5 |
7 |
|
H |
1 |
2 |
Fonte: o autor
Para analisarmos se há correlação entre as variáveis X e Y, inicialmente, os dados são representados em um gráfico cartesiano de pontos, que chamamos de diagrama de dispersão. Cada ponto do gráfico corresponde a um aluno e é marcado segundo seu valor para X e para Y (Figura 1).
Figura 1 - Gráfico de dispersão sobre a relação entre horas de estudo (X) e nota na disciplina de bioestatística (y)

Fonte: o autor.
Analisando a Figura 1, podemos observar que os alunos que se dedicaram estudando por mais horas tiveram um desempenho melhor, e os que dedicaram menos horas ao estudo, a ter um desempenho pior na prova. Entretanto podemos observar que temos algumas exceções, como o aluno “C” que se dedicou horas de estudo e sua nota foi 4. Isso significa que, embora pareça existir uma correlação entre estas duas variáveis, ela não é perfeita.
Para sabermos com mais precisão, existe outra maneira, que é avaliar a correlação e usar um coeficiente, que tem a vantagem de ser um valor numérico.
O coeficiente de correlação produto-momento (r) é uma medida da intensidade de associação existente entre duas variáveis quantitativas, e sua fórmula de cálculo foi proposta por Karl Pearson em 1896. Por essa razão, é também denominado coeficiente de correlação de Pearson. Por ter sido o primeiro a ser proposto (vários outros foram criados depois), muitas vezes r recebe simplesmente nome de coeficiente de correlação (MARTINEZ, 2015, p. 85).
O coeficiente de correlação pode variar entre -1 e +1. Quando temos valores negativos de r, temos correlação do tipo inversa, ou seja, à medida que X aumenta Y diminui. Já quando temos valores positivos para r ocorrem quando a correlação é direta, ou seja, X e Y variam no mesmo sentido. Por exemplo, temos que as taxas sanguíneas de insulina e glicose apresentam correlação negativa; enquanto a taxa do hormônio glucagônio tem correlação positiva com a glicemia (MARTINEZ, 2015).
É importante salientar que, quando temos uma correlação linear negativa, não significa que é uma correlação ruim , apenas o sentido do gráfico será decrescente. O valor máximo (tanto r = +1 como r = -1) é obtido quando todos os pontos do diagrama estão em uma linha reta inclinada. Quando temos uma correlação linear igual a r +1, significa que temos uma correlação linear perfeita e positiva, como você pode observar na Figura 2.
Figura 2 - Correlação quando r = +1 / Fonte: o autor.
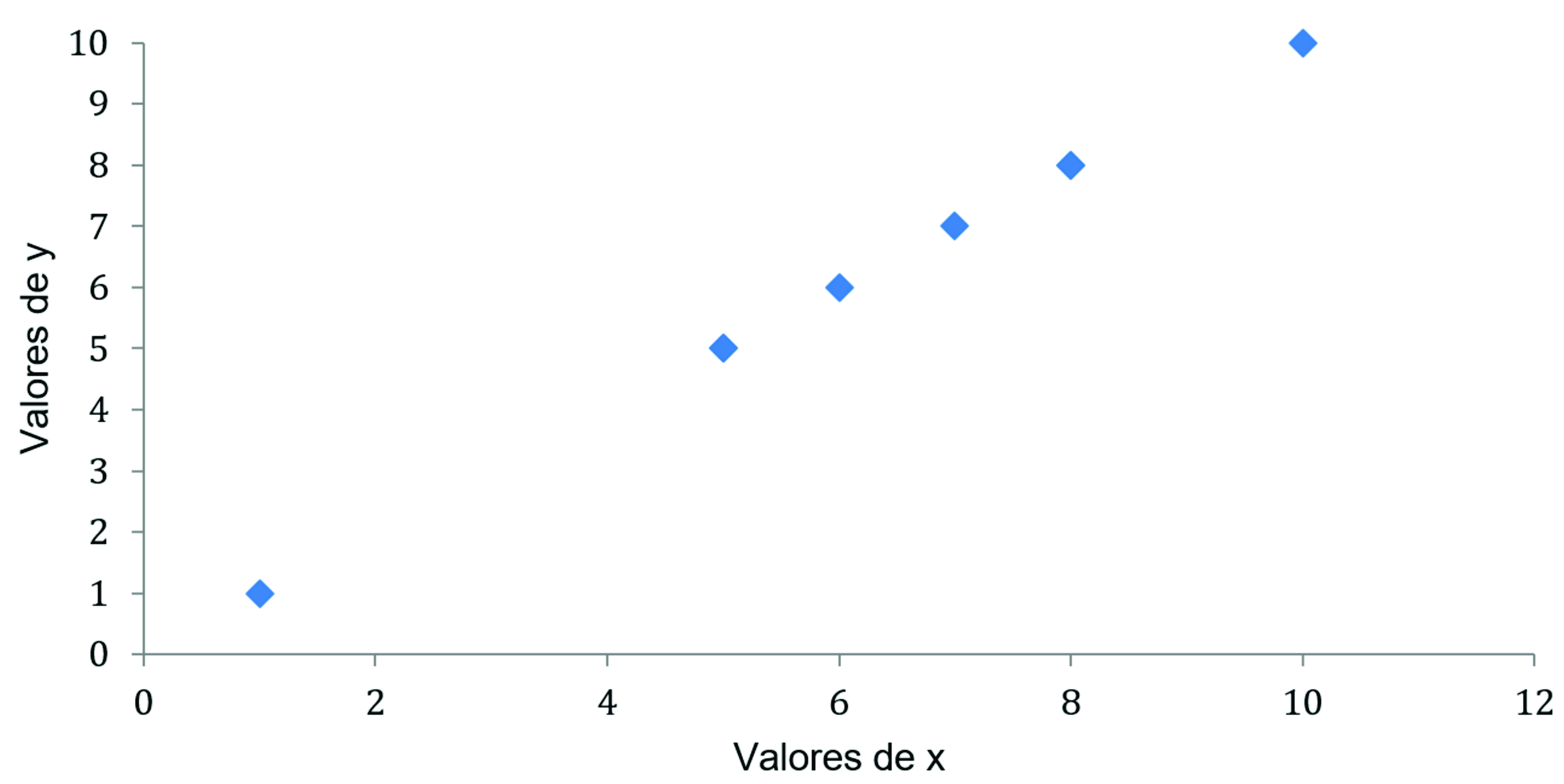
Quando temos uma correlação linear igual r -1, significa que temos uma correlação linear perfeita e negativa, como você pode observar na Figura 3.
Figura 3 - Correlação quando r = -1 / Fonte: o autor.
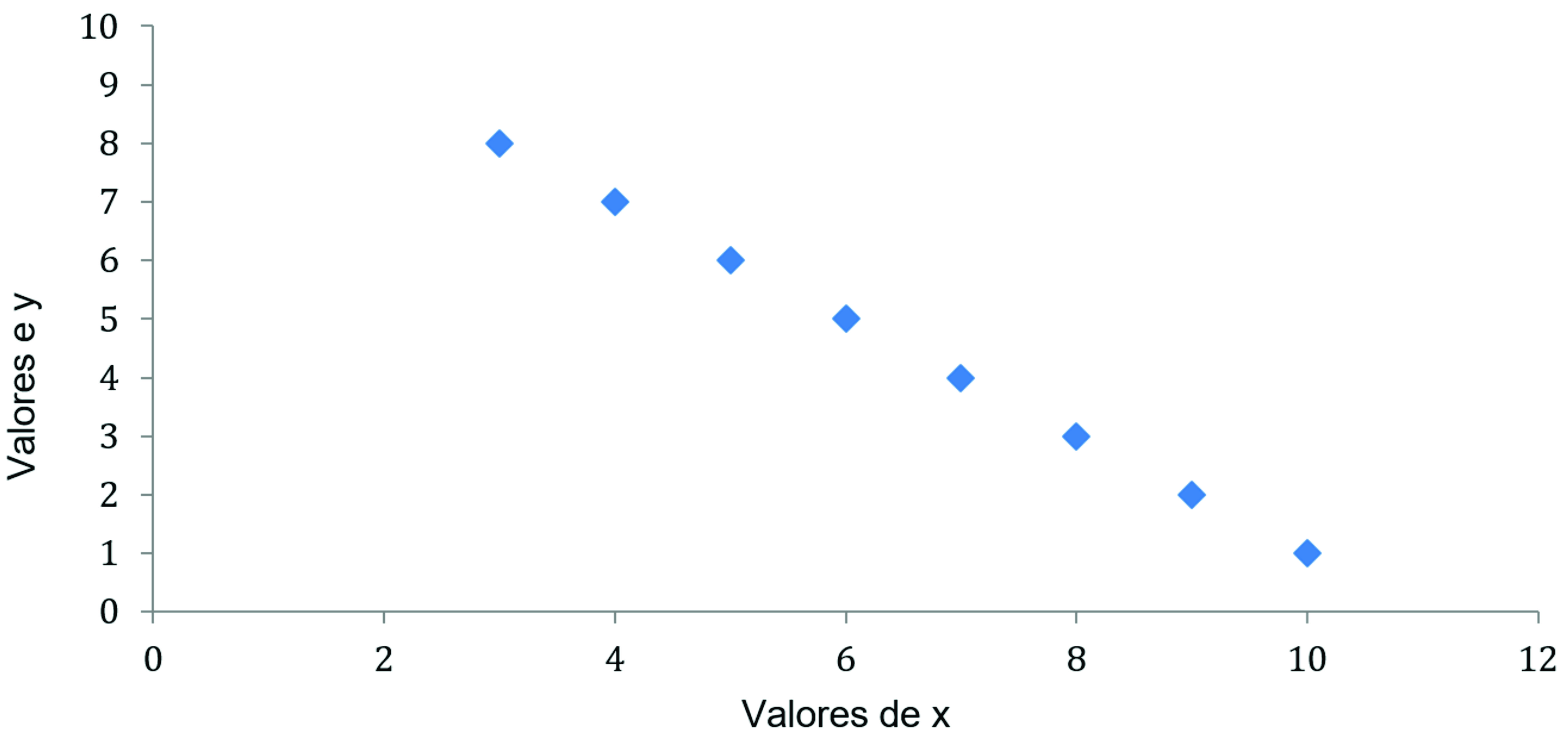
Por outro lado, quando não existe correlação entre X e Y, os pontos se distribuem de maneira que não temos uma relação, podendo ser em formato de nuvens circulares ou formatos não definidos, não tendo uma tendência crescente ou decrescente (Figura 4).
Figura 4 - Correlação quando r = 0,09 / Fonte: o autor.

As associações (X e Y) de grau intermediário (r entre 0 e |1|) apresentam-se como nuvens inclinadas, de forma elíptica, como podemos observar na Figura 5.
Figura 5 - Correlação quando r = 0,65 / Fonte: o autor.

O que significa, então, esses valores de r? Observe a Figura 6 a seguir, que traz uma correlação igual a r = 0,56.
Figura 6 - Correlação quando r = 0,55 / Fonte: o autor.

Segundo Zou et al. (2003) a proposta para interpretação do coeficiente de correlação linear (r) pode ser observada no Quadro 1.
Quadro 1 - Interpretação do coeficiente de correlação linear
|
Valor do coeficiente de correlação linear (r) |
Direção e força da associação |
|---|---|
|
-1,0 |
Perfeita e negativa |
|
-0,8 |
Forte e negativa |
|
-0,5 |
Moderada e negativa |
|
-0,2 |
Fraca e negativa |
|
0 |
Ausência de associativa |
|
0,2 |
Fraca e positiva |
|
0,5 |
Moderada e positiva |
|
0,8 |
Forte e positiva |
|
1,0 |
Perfeita e positiva |
Fonte: adaptado de Zou et al . (2003).
Zou et al . (2003) interpretam o sinal do coeficiente de correlação como a direção da associação. Os coeficientes de correlação linear que são maiores do que zero apresentam correlações positivas (quanto maior X, maior Y), e coeficientes menores que zero indicam correlações negativas (quanto maior X, menor Y) . Já a correlação igual a zero indica que não existe uma correlação linear.
É importante salientar que a interpretação de r pode variar de acordo com a experiência de autores, principalmente as intermediárias (-0,8, 0,5, -0,2, -0,3 e outros), o que não muda é que +1 e -1 são correlações perfeitas e zero não há correlação linear. Para facilitar nosso entendimento, analise na Figura 7 que quanto mais próximo aos extremos (-1 e +1) mais forte é a correlação, e, à medida que se aproxima de zero, a correlação vai ficando mais fraca.
Figura 7 - Correlação quando r = 0,55 / Fonte: o autor.

A existência de uma correlação baixa, entretanto, não deve conduzir ao descarte das variáveis de estudo. Um coeficiente de correlação linear baixo indica apenas que não há uma grande semelhança de comportamento linear entre as variáveis do estudo. Assim, devem-se estudar outros tipos de relações entre elas. (E. Z. Martinez)
Então, podemos concluir que uma correlação igual a -0,90 é mais forte do que uma correlação igual a 0,40? Sim, porque -0,90 está mais próximo de -1, e 0,40 está mais próximo de zero. Mas como encontramos o coeficiente de correlação de Pearson? É representada pela letra “r” e determinado pela seguinte equação:

Em que: r = Coeficiente de correlação de Pearson (a ser encontrado) Σx = valores da somatória da variável x Σy = valores da somatória da variável y Σx.y = valores da somatória da variável x multiplicado pela variável y Σx2 = valores da somatória da variável x ao quadrado Σy2 = valores da somatória da variável y ao quadrado
Agora que temos a equação que determina o coeficiente de Pearson, vimos que se trata de uma equação bem complexa, mas fique tranquilo(a), querido(a) aluno(a), resolveremos juntos o passo a passo. Vejamos um exemplo: um professor de ciências biológicas deseja saber se existe correlação entre o tempo dedicado ao estudo e o desempenho dos alunos na disciplina de Bioestatística. Assim, ele selecionou oito alunos, assim, podemos observar o número de horas (X) e a nota obtida na prova de Bioestatística (Y) para cada aluno.
Tabela 2 - Relação entre as horas de estudo e nota na disciplina de Bioestatística
|
Acadêmico |
Horas de Estudo (x) |
Nota em Bioestatística (y) |
|---|---|---|
|
A |
8 |
10 |
|
B |
8 |
8 |
|
C |
6 |
4 |
|
D |
5 |
8 |
|
E |
4 |
6 |
|
F |
7 |
9 |
|
G |
5 |
7 |
|
H |
1 |
2 |
Fonte: o autor.
Para facilitar nosso cálculo, você deve ter percebido que vamos precisar elevar todos os valores de X ao quadrado, todos os valores de Y ao quadrado e somar tudo isso, então, vamos reescrever a tabela, com essas colunas. Observe a seguir (Tabela 3):
Tabela 3 - Relação entre as horas de estudo e nota na disciplina de Bioestatística
|
Acadêmico |
Horas de Estudo (x) |
Nota em Bioestatística (y) |
x2 |
y2 |
x.y |
|---|---|---|---|---|---|
|
A |
8 |
10 |
64 |
100 |
80 |
|
B |
8 |
8 |
64 |
64 |
64 |
|
C |
6 |
4 |
36 |
16 |
24 |
|
D |
5 |
8 |
25 |
64 |
40 |
|
E |
4 |
6 |
16 |
36 |
24 |
|
F |
7 |
9 |
49 |
81 |
63 |
|
G |
5 |
7 |
25 |
49 |
35 |
|
H |
1 |
2 |
1 |
4 |
2 |
|
TOTAL |
44 |
54 |
280 |
414 |
332 |
Fonte: o autor.
Agora que temos o total e já determinamos os valores que precisamos, faremos a substituição na equação para determinar o coeficiente de Pearson.

Substituindo os valores na equação, temos:

Portanto, existe uma correlação linear e forte entre as horas de estudo (x) e a nota na prova de B0ioestatística (y) uma vez que o valor encontrado de r é igual a 0,81. Você achou complicado utilizar esta equação? Ajudaremos com uma maneira simples, em que você consegue tirar a prova real utilizando o Microsoft Excel®, mas lembre-se, agora você está em processo de aprendizagem e, ao fazer cálculos passo a passo da forma algébrica, você estará exercitando seu raciocínio lógico, isso ajudará você na tomada de decisões. Utilizando o Microsoft Excel®, basta reescrever a tabela na planilha, vá em inserir função – Estatística – Correl, onde abrirá para você a função = correl, em seguida, no item matriz um, selecione todas as notas da variável X (sem cabeçalho e total), clique em matriz 2 e selecione todas as notas da variável Y (sem cabeçalho e total).
Quando falamos em relações lineares entre as variáveis X e Y, significa que, ao utilizarmos o coeficiente de correlação de Pearson, estamos nos referindo a uma situação em que uma variável é, direta ou inversamente, proporcional a outra (CRESPO, 2009). Vimos em nosso exemplo, que quanto às horas dedicadas a estudos tem uma relação forte com a nota da disciplina de Bioestatística.
Portanto, é de fundamental importância construir um gráfico de dispersão entre as variáveis antes de calcularmos o coeficiente de correlação (que já fizemos anteriormente, na Figura 7), e, então, observarmos se é realmente adequado utilizarmos essa medida de associação.
Figura 8 - Gráfico de dispersão sobre a relação entre horas de estudo (X) e nota na disciplina de Bioestatística (Y) / Fonte: o autor.

Se a dispersão que é apresentada no gráfico permite visualizar uma reta imaginária passando pelos pontos, entendemos que há a sugestão de uma relação linear (ainda que essa reta tenha uma inclinação pequena).
Um erro comum entre as pessoas que estão aprendendo bioestatística é pensar que o coeficiente de correlação serve para testar se há uma relação linear entre as variáveis X e Y. Quando usamos o coeficiente de correlação, já partimos do princípio de que a possível relação entre as variáveis se dá de forma linear, por isso, a importância do gráfico de dispersão, assim, o coeficiente de Pearson serve para medir o tamanho dessa associação linear, e não para verificar se há linearidade na relação entre X e Y.
A resposta a esta pergunta não é simples. Em nenhuma situação podemos eliminar observações de nosso banco de dados com o propósito de deixar os resultados mais interessantes ou de destacar possíveis associações entre as variáveis que valorizariam nosso estudo, principalmente nas áreas biológica e da saúde, que podem trazer dados que podem orientar o direcionamento de uma pesquisa, além de não ser uma conduta ética por parte do pesquisador. Para isso, é importante que você vá novamente aos dados coletados, faça comparação com os dados da pesquisa de campo, verifique os questionários, os prontuários, a fonte original dos dados para, então, verificar a possibilidade de erros de digitação ou anotação. Ainda que não fosse esse o erro encontrado, não é correto eliminá-lo, arbitrariamente. É de suma importância buscar outras informações sobre aquele dado para possa entender se realmente ele pertence àquela população de interesse do estudo.
Depois que calculamos a correlação linear, podemos ter o interesse em determinar a Regressão Linear . A análise de regressão explicita em uma equação matemática a forma da relação entre uma variável chamada dependente e uma ou mais variáveis chamadas independentes , ou seja, quando temos o interesse, estudo da regressão aplica-se à quelas situações em que há razões para supor uma relação de causa-efeito entre duas variáveis quantitativas e se deseja expressar, matematicamente, essa relação.
O termo regressão deve-se a Francis Galton, que publicou, em 1886, um artigo no qual tentou explicar por que pais de alta estatura tinham filhos com estatura em média mais baixa do que a deles e pais de baixa estatura tinham filhos em média mais altos. Esse fenômeno foi chamado de regressão à média, termo que, apesar de inadequado para expressar a dependência entre duas variáveis quantitativas, acabou sendo incorporado pelo uso à linguagem estatística (MARTINEZ, 2015, p. 103).
Para entender melhor, em nosso estudo, o professor de Enfermagem quis saber se há relação entre o tempo de estudo e nota na prova da disciplina Bioestatística. A variável dependente é a nota da prova, pois, supostamente, recebe o efeito do tempo dedicado aos estudos. Por sua vez, o tempo de estudo (X) é a variável independente, dado que, supostamente, ela exerce algum efeito sobre a variável dependente . Sendo assim, os objetivos da regressão linear são, segundo Martinez (2015): 1. Avaliar uma possível dependência de y em relação a x. 2. Expressar matematicamente está relação por meio de uma equação.
Vamos considerar que a variável independente Y de interesse é quantitativa contínua. O modelo de regressão simples envolve uma única variável independente X. A equação para determinar a regressão linear é dada por:

Em que:
ŷ = valor predito da variável resposta
a = constante de regressão que representa o intercepto entre a
linha de regressão e o eixo y
b = coeficiente linear de regressão da variável resposta y em
função da variável explicativa x inclinação da reta; taxa de
mudança na variável y por unidade de mudança na variável x
x = valor da variável explicativa (variável independente)
O coeficiente de regressão “b” fornece uma estimativa da
variação esperada de y a partir da variação de uma unidade em
x (BARBETTA et al., 2014). A partir desta equação, é possível
encontrar os valores preditos para y e a reta de regressão.
Vimos, anteriormente, que a relação entre x e y pode ser
mostrada por um diagrama de dispersão.
Para calcular a regressão linear, vamos determinar “a” e “b”.
Assim, utilizaremos as equações:

Em que:
Σx = valores da somatória da variável x
Σy = valores da somatória da variável y
Σx.y = valores da somatória da variável x multiplicado pela
variável y
Para determinar “a”, utilizaremos a equação a seguir:

Em que:
Y = média de Y
X = média de X
b = valor que é determinado por equação e encontrado valor de
“b”. Para encontrarmos as médias de Y e X , basta:

Em que:
y = somatória de todos os valores de y
n = número total de elementos

Em que:
x = somatória de todos os valores de x
n = número total de elementos
Agora que já sabemos como determinar a correlação linear, relembraremos nosso exemplo: um professor de Enfermagem deseja saber se existe correlação entre o tempo dedicado ao estudo e o desempenho dos alunos na disciplina Bioestatística. Assim, ele selecionou oito alunos, assim, podemos observar o número de horas (X) e a nota obtida na prova de Bioestatística (Y) para cada aluno (apresentaremos a tabela a seguir, com as colunas necessárias para calcular a regressão linear).
Tabela 4 - Relação entre as horas de estudo e nota na disciplina de Bioestatística
|
Acadêmico |
Horas de Estudo (x) |
Nota em Bioestatística (y) |
x2 |
x.y |
|---|---|---|---|---|
|
A |
8 |
10 |
64 |
80 |
|
B |
8 |
8 |
64 |
64 |
|
C |
6 |
4 |
36 |
24 |
|
D |
5 |
8 |
25 |
40 |
|
E |
4 |
6 |
16 |
24 |
|
F |
7 |
9 |
49 |
63 |
|
G |
5 |
7 |
25 |
35 |
|
H |
1 |
2 |
1 |
2 |
|
TOTAL |
44 |
54 |
280 |
332 |
Fonte: o autor.
Com os resultados, podemos calcular o valor de “b”, utilizando a equação:

Substituindo os valores na equação:

Agora, determinaremos “a”, utilizando a equação a seguir:

Primeiro, teremos que encontrar a média de X e Y:

Agora que temos o valor de b = 0,92; Y = 675 ,e X = 55 ,, determinaremos “a”:

Agora, com todos os valores necessários, determinaremos a equação de regressão linear:
Substituindo, temos:

Com a equação da reta, podemos substituir dois pontos quaisquer por X para traçar a reta. A Figura 9 apresenta-nos o gráfico de dispersão com a reta de regressão linear.
Figura 9 - Gráfico de dispersão e reta de regressão linear sobre a relação entre horas de estudo (x) e nota na disciplina de bioestatística / Fonte: o autor.

Podemos observar como o valor de r encontrado, anteriormente, foi igual a 0,80, e o valor de “bx” é positivo, nossa reta ajustada tem sentido crescente. Caso nosso valor de r fosse negativo, nossa reta ajustada teria o sentido decrescente. Outro ponto importante em uma análise utilizando ferramentas estatísticas é a inferência. Imagine que um profissional da saúde trabalha em um laboratório e está conduzindo um estudo cujo objetivo é analisar se um novo medicamento pode ser capaz de trazer bons resultados ao tratamento de determinada doença . Para realizar essa pesquisa, este profissional selecionou uma amostra de 80 pessoas portadoras da doença, e estas foram divididas em dois grupos com 40 pessoas cada. As pessoas do grupo A foram submetidas ao medicamento que está sendo avaliado, as pessoas do grupo B, receberam um placebo . Os resultados estão apresentados na Tabela a seguir:
Tabela 5 - Resultados do estudo

Fonte: o autor.
Podemos observar que: 20 4050 % das pessoas que estão no grupo A, responderam ao tratamento que está sendo avaliado, já 10 4025% das pessoas alocadas no grupo B responderam ao tratamento com o medicamento sem o princípio ativo (placebo). Dessa maneira, a razão entre essas porcentagens é 50252 %() / %() grupoAgrupoB = , isto é, podemos concluir que entre as 80 pessoas que tem a doença e estão participando do estudo, se utilizarem o medicamento (da pesquisa) tem o dobro de chances de responder à doença quando comparados ao grupo B.
Inicialmente, o resultado obtido descreve apenas as 80 pessoas que compuseram esta amostra. No entanto nosso intuito é que os nossos resultados tragam valor para todas as pessoas que fazem parte da população e que tenham essa doença, não importando se foram selecionados, ou não, para compor a amostra da pesquisa. Para obtermos isso, fazemos uso da inferência estatística , ferramenta usada para extrapolar os achados de nossa amostra para todos os indivíduos que fazem parte da população (MARTINEZ, 2015).
A Figura 10 apresenta-nos o processo pelo qual obtemos conclusões sobre uma população (N) a partir de dados obtidos, por meio de uma amostra (n).
Figura 10 - Representação de uma inferência estatística / Fonte: o autor.

Para estudarmos a inferência estatística, relembraremos alguns conceitos já estudados anteriormente (CRESPO, 2009):
Conjunto de elementos que tem, pelo menos, uma característica em comum.
Subconjunto da população, parte da população.
É representativa da população, sendo válidos os resultados obtidos, por meio do uso da inferência estatística.
Outro conceito importante que precisamos estudar aqui na inferência estatística é o Parâmetro , essencial para entendermos a inferência estatística. Trata-se de valor calculado a partir de uma população, ou seja, usando todos os elementos (MARTINEZ, 2015). Por exemplo: um professor de Farmácia quer estudar a altura (em cm) das crianças que estão cursando a 1ª série em determinado município. A população inclui todas as crianças deste município. A média da altura encontrada (em cm), que é calculada a partir da análise do peso de todas as crianças da população é um parâmetro.
Pedimos que tome cuidado para não confundir Parâmetro com Variável. O parâmetro, como já vimos, é uma característica numérica de uma população, já uma variável é uma característica dos indivíduos que estamos pesquisamos. Segundo Parenti, Silva e Silveira (2017), o parâmetro é um número fixo, já os valores de uma variável são passíveis de variação de um indivíduo a outro. Por exemplo: entre os alunos estudados, a idade e o prato preferido são variáveis , já a média da altura de todos os alunos de determinada cidade é um parâmetro .
Nem sempre, na prática, conseguiremos trabalhar com parâmetros, trabalharemos com amostra. Assim, a média amostral, que é resultante de uma amostra de tamanho n, é uma estimativa da média populacional. Dessa maneira, as estimativas são quantidades calculadas da amostra com a finalidade de representar um parâmetro de interesse (MARTINEZ, 2015).
A diferença entre uma média populacional (parâmetro) da média
amostral (estimativa) é denotada por:
a) média populacional: representado pela letra grega μ.
b) média amostral: representado por “xis barra” X .

“ Quando conduzimos uma pesquisa com base em uma amostra de n indivíduos, podemos calcular o valor de x com base nas observações amostrais. Mas, obviamente, não podemos calcular o valor de n, dado que não temos à nossa disposição todos os elementos da população. Assim, entendemos que o parâmetro é um número fixo, mas geralmente não conhecemos seu valor .
- MARTINEZ, 2015, p. 166Assim, as principais ferramentas da inferência estatística são os intervalos de confiança e os testes de hipóteses. Podemos utilizar da seguinte forma:
utilizamos quando o objetivo do estudo é voltado à estimação de um parâmetro.
utilizados quando o objetivo do estudo envolve hipóteses sobre um parâmetro de interesse.
O intervalo de confiança para a média (μ) de uma população é construído em torno da estimativa pontual X .
Para construir este intervalo, fixamos uma probabilidade “ 1 – α” de que o intervalo construído contenha o parâmetro populacional. Desta forma α será a probabilidade de que o intervalo obtido não contenha o valor do parâmetro, isto é , α será a probabilidade de erro. Sabendo-se que a média da amostra apresenta uma distribuição normal (média μ e desvio padrão σ / ) se a população de onde for extraída a amostra for normal (ou se a amostra for superior a 30 e retirada de qualquer população) de média μ e de desvio padrão σ, podemos então utilizar a curva normal para estabelecer os limites para o intervalo de confiança (BARBETTA, 2014).
Para entendermos melhor o intervalo de confiança, temos que entender que a margem de erro é a sua peça chave, ou seja, no meio do intervalo de confiança é que fica a média amostral. Observe na equação a seguir:

A distância que temos entre a média e o limite do intervalo de confiança é exatamente igual à margem de erro. É importante salientar que o nível de confiança deve ser selecionado, previamente, pelo pesquisador, e que a média populacional fica dentro do intervalo de confiança .
Para calcular o limite superior XLS e inferior XLI do intervalo de confiança para nível de confiança igual a (1 – α) usa-se a seguinte expressão oriunda da discussão sobre as áreas embaixo da curva normal e a distribuição normal padronizada:

Em que:
X = média
Zc = Z crítico - valor a ser encontrado na Tabela de Curva Normal (Tabela Z)
S = desvio padrão
n = número de elementos da amostra
α = intervalo de confiança (ex.: 90%, 95%, 98%).
Você verá que é bem simples este cálculo, e temos duas situações:
1º caso: para σ conhecido ou amostra grande (n ≥ 30): para determinar, utilizaremos a equação a seguir:

Em que:
X = média
Zc = “Z” crítico (encontrado na Tabela Z)
σ = desvio padrão
n = número de elementos da amostra.
Vejamos um exemplo: um professor fez uma pesquisa com 100 alunos, e a média de idade deste grupo de alunos é de 24 anos. Sabendo-se que o desvio padrão é igual a quatro anos, determine o intervalo de 95% de confiança para a média. Para a resolução, devemos entender que o que calcularemos nessa equação é apenas: Zc n . s , pois a média que já é dada, nós somaremos e diminuiremos pelo intervalo encontrado.
resolver a equação (margem de erro):

agora que temos a margem de erro, determinamos o intervalo de confiança, somaremos com a média o valor da margem de erro e diminuiremos a média pela margem de erro, utilizando:

Ou

Também pode ser escrito desta maneira:

Figura 11 - Curva de Gauss

Fonte: o autor.
Tabela 6 - Tabela de distribuição Normal Reduzida

Fonte: Crespo (2009, p. 218). Encontramos o valor de 1,96. Você poderá encontrar qualquer valor utilizando somente a tabela Z.
2º caso : Intervalo de confiança para a média (σ desconhecido): quando desejamos estimar a média de uma população normal com variância desconhecida, temos duas situações:
a) Se n >30: utilizamos a distribuição normal com estimador s2 de σ2 (visto anteriormente).
b) Se n ≤ 30: utilizamos a distribuição t de Student.
Vejamos um exemplo: uma amostra de dez pessoas com as idades: 9, 8, 12, 7, 9, 6, 11, 6, 10 e 9, tem, em média, 8,7, um desvio padrão 2 e foi extraída de uma população Normal. Construa um intervalo de confiança para média ao nível de 95%.
Utilizando a equação do intervalo de confiança para t de Student, temos:

Em que:
X = média
tcritíco = valor a ser encontrado na Tabela t de Student
S = desvio padrão
n = número de elementos da amostra
Utilizaremos a Tabela t de Student em um teste bicaudal que podemos observar na Figura 12.
Figura 12 - Representação do teste bicaudal para Tabela t student / Fonte: o autor.

Para resolver nosso exercício, temos que encontrar nosso tcrítico, assim, temos:
Veja a Figura 13.
Figura 13 - Representação do teste bicaudal para Tabela t student / Fonte: o autor.

Como você pode perceber, os 95% é o que temos em nosso exercício, e os 5% foram divididos nas duas áreas do gráfico, representando 2,5% em cada cauda. Mas, para utilizar a tabela t Student, consideraremos que 5% teste são bicaudal, e procuraremos esse valor na tabela. Apenas mais um detalhe, antes de ir à tabela, é importante que você entenda que o grau de liberdade é igual a n – 1, portanto, temos 10 elementos, para o grau de liberdade teremos: 10-1 = 9. Assim, buscaremos “9” quanto ao grau de liberdade.
Vamos procurar a linha 9 e a coluna 5% em nossa tabela T Student apresentada a seguir:
Tabela 7 - Tabela t de Student - Probabilidade para um teste bicaudal

Fonte: Barbeta et al. (2014, p. 300).
Assim o valor encontrado é igual a 2,2622, agora, resolveremos nosso exercício.
Resolvendo nosso exercício, voltando a equação, temos:

Portanto: IC = [7,27; 10,13].
Assim, a probabilidade de este intervalo 7,27 a 10,13 conter a média populacional (verdadeira idade) das pessoas é igual a 95%.
Também temos um método para fazer inferências sobre as populações: os testes de hipóteses . Ao admitirmos um valor hipotético para um parâmetro populacional e, baseados nas informações coletadas em uma amostra, podemos realizar o teste de hipóteses, na qual nossa decisão poderá: aceitar ou rejeitar a hipótese. É importante frisar que esta decisão está sujeita a erros, baseado em resultados de uma amostra, muitas vezes, não é possível tomar decisões que estejam totalmente corretas. No entanto, podemos dimensionar a chance, a probabilidade, o risco em aceitar ou rejeitar uma hipótese (MARTINEZ, 2015).
Uma hipótese estatística refere-se à suposição do parâmetro populacional, como:
A altura média da população brasileira é de 1,65 m, isto é: H: μ = 1,65 m.
A variância populacional dos salários vale R$1.000,00, isto é: H: σ2 = 1.000,00.
A proporção de paulistas com a doença X é de 40%, ou seja: H: p = 0,40.
A distribuição de probabilidades dos pesos dos alunos de uma instituição de ensino é normal
A chegada de navios ao porto de Santos é descrita por uma distribuição de Poisson.
Isso significa que as hipóteses estatísticas são estabelecidas pelos critérios do pesquisador, baseado no que ele está buscando, ou seja, com informações teóricas, muitas vezes. Já o teste de hipótese em si, trata-se de uma regra de decisão para aceitar ou rejeitar uma hipótese estatística com base nos elementos amostrais.

São dois os tipos de hipóteses: designa-se H0, denominada
hipótese nula, a hipótese estatística a ser testada, e H1, a
hipótese alternativa. A hipótese nula expressa uma igualdade,
enquanto a hipótese alternativa é dada por uma desigualdade.
São exemplos de hipóteses para um teste estatístico:
Existem dois tipos possíveis de erros quando fazemos um teste estatístico para aceitar ou rejeitar H0. Nós podemos rejeitar a hipótese H0, quando ela é verdadeira, ou aceitar H0, quando ela é falsa (MARTINEZ, 2015). O erro de rejeitar H0, sendo H0 verdadeira, é denominado Erro tipo I, e a probabilidade de se cometer o Erro tipo I é designada α. Por outro lado, o erro de aceitar H0, sendo H0 falsa, é denominado Erro tipo II, e a probabilidade de cometer o Erro tipo II é designada β.
Os possíveis erros e acertos de uma decisão com base em um teste de hipótese estatístico estão apresentados a seguir:
trata-se do erro que se comete ao rejeitar a hipótese H0 quando ela é verdadeira. O nível de significância do teste é designado por α, que é a probabilidade de se cometer o erro do tipo 1.
é o erro que se comete ao aceitar a hipótese H0 quando ela é falsa. Rejeitar H0 implica a aceitação de H1 e vice-versa. A probabilidade de cometer um erro do tipo 2 é dada por 1 – α.
Dentro do teste de hipóteses, temos as regiões de aceitação e rejeição, a saber:
Como tipos de testes de hipóteses temos: Bilateral, Unilateral à Esquerda, Unilateral à Direita, sendo a região crítica (ou região de rejeição) que corresponde aos valores da estatística de teste que nos levam a rejeitar a hipótese nula. Dependendo da afirmativa em teste, a região crítica poderia estar nas duas caudas extremas, poderia estar na cauda esquerda, ou poderia estar na cauda direita.
Teste bilateral
A região crítica está nas duas regiões extremas (caudas) sob a curva (Figura 14).
Figura 14 - Teste bilateral / Fonte: o autor.

Teste unilateral à direita
A região crítica está na região extrema (cauda) direita sob a curva (Figura 15).
Figura 15 - Teste unilateral à direita / Fonte: o autor.

Teste unilateral à esquerda
A região crítica está na região extrema (cauda) esquerda sob a curva (Figura 16).
Figura 16 - Teste unilateral à esquerda / Fonte: o autor.

Depois de apresentarmos os conceitos fundamentais dentro de um teste de hipótese, você verá que não é um teste complicado. A seguir, apresentaremos o roteiro para realização de um teste de hipóteses.
estabelecer a hipótese nula H0.
estabelecer a hipótese alternativa H1.
fixar o nível de significância α: em que definimos o nível de confiança para um intervalo de confiança, como a probabilidade 1 – α. Escolhas comuns para α são 0,05; 0,01 e 0,10, com 0,05 sendo a mais comum.
determinar a região de rejeição da hipótese nula.
extrair a amostra e calcular o valor da estatística correspondente.
rejeitar ou aceitar H0, conforme o valor da estatística amostral cair em R. R. ou R.
Os valores críticos de z relativos aos níveis de significância usados com maior frequência podem ser observados a seguir (valores já retirados da Tabela Z de distribuição normal reduzida):
|
Nível de significância α |
0,10 |
0,05 |
0,01 |
|---|---|---|---|
|
Valores críticos de z para testes unilaterais |
± 1,28 |
± 1,64 |
±2,33 |
|
Valores críticos de z para testes bilaterais |
± 1,64 |
± 1,96 |
± 2,58 |
Para entendermos este passo a passo, vejamos um exemplo: supondo que um professor de ciências biológicas deseja testar H0: μ = 20 contra H1: μ > 20, sabendo que o desvio padrão da população é igual a 4 e a amostra testada foi de 16 elementos:
estabelecer a hipótese nula H0: H0: μ = 20
estabelecer a hipótese alternativa H1: H1: μ > 20
fixar o nível de significância α: Para esse exercício vamos admitir que α = 0,05 = 5%.
determinar a região de rejeição da hipótese nula: Como H1: μ > 20, vamos utilizar o teste unilateral à direita, que podemos observar na Figura 17.
extrair a amostra e calcular o valor da estatística correspondente: temos a amostra de 16 elementos, desvio padrão igual a 4, e determinar o Zcalculado. Obs.: não temos a média amostral para este exercício. Como estabelecemos 0,05 como nível de significância, o z será igual a 1,64.

Em que:
Zcalculado = valores da tabela Z
X = média da amostra
μ0 = é a média da população (hipótese a ser testada)
σ = desvio padrão da população
n = número de elementos da amostra
Substituindo os valores na equação, temos:

rejeitar ou aceitar H0, conforme o valor da estatística amostral cair em R. R. ou R. A. Nesse exercício, temos: Rejeitar H0 quando > 21,64 Não Rejeitar H0 quando ≤ 21,64
Vamos a outro exemplo para sua melhor compreensão?
Um professor de Biomedicina fez uma pesquisa com um componente que será utilizado em laboratório, tem uma vida média de 50 meses e um desvio padrão de 50 meses. Ao retirar uma amostra de 36 componentes, que foram obtidas a partir desta população, percebeu que o componente tem em média 48 meses de vida . Assim, utilizando o teste de hipóteses, podemos afirmar que a média desta população é diferente de 50 ? Considere o nível de 5% para resolução.
Nesse caso, queremos obter o teste de hipóteses com uma média diferente de 50, certo? Então, utilizaremos o teste bilateral. Resolvendo o exercício passo a passo, temos:
estabelecer a hipótese nula H0:

extrair a amostra e calcular o valor da estatística correspondente: temos a amostra de 36 componentes, com uma população de 50 componentes, o tempo de vida médio amostral é de 48 meses. Como estabelecemos 0,05 como nível de significância (para teste bilateral), o z será igual a 1,96.

Figura 18 - Teste bilateral / Fonte: o autor.

Muitos fenômenos biológicos podem ser expressos por equações matemáticas, que podem facilitar o entendimento das relações entre grandezas conhecidas e aquelas que queremos estimar, como o ajustamento de curvas, que é um instrumento imprescindível quando sabemos que a medida cefálica de um animal arisco (ave, morcego, peixe etc.) apresenta uma afinada relação com outras medidas, entre outras aplicações. Nossa roda de conversa abordará um pouco desta aplicação. Você sabia que um professor pode, também, analisar (utilizando técnicas estatísticas) a compreensão dos seus alunos quanto aos conteúdos trabalhados? Para isso, recomendamos a leitura do artigo a seguir, em que foi avaliada a compreensão em testes de hipóteses de alunos que cursaram a disciplina Bioestatística em uma Universidade pública no estado de Minas Gerais. Para tal, 23 alunos responderam a um teste sobre o tema, do qual foram analisadas neste texto duas questões que versam sobre o estabelecimento/ formulação de hipóteses. Estudante, acesse seu ambiente de estudo para acessar o artigo.
Você percebeu, caro(a) estudante, que a correlação e a regressão linear poderão ajudá-lo(a) como professor(a). Você pode ter uma turma, analisar duas disciplinas e fazer projeções sobre as possíveis notas de seus alunos, desde que tenham uma correlação linear forte. Você, também, identificou como as técnicas estudadas em Bioestatística sobre a inferência poderão, por meio de testes, construir um modelo de aceitação ou rejeição de uma hipótese.
Espero que tenha tirado máximo proveito desse conteúdo.
ANDERSON, L. O. et al. Identification of priority areas for reducing the likelihood of burning and forest fires in South America August to October 2020. 16 p. São José dos Campos: SEI/Cemaden, 2020.
ARANGO, H. G. Bioestatística: teórica e computacional: com banco de dados reais em disco. 3. ed. Reimpr. Rio de Janeiro: Guanabara Koogan, 2011.
BARBETTA, P. A. Estatística aplicada às Ciências Sociais. 9. ed. Florianópolis: UFSC, 2014.
CRESPO, A. A. Estatística. 19. ed. São Paulo: Atlas, 2009.
MARTINEZ, E. Z. Bioestatística para os cursos de graduação da área da saúde. São Paulo: Blücher, 2015.
PARENTI, T. M. S.; SILVA, J. S. F. da.; SILVEIRA, J. Bioestatística. Porto Alegre: SAGAH, 2017.
ZOU, K. H.; TUNCALI, K.; SILVERMAN, S. G. Correlation and simple linear regression. Radiology, v. 227, n. 3, p. 617-622, 2003.