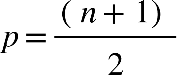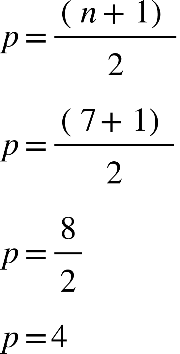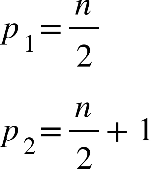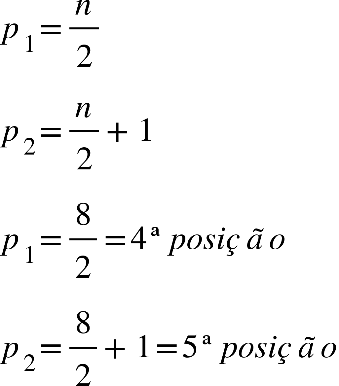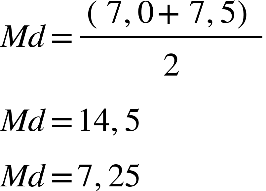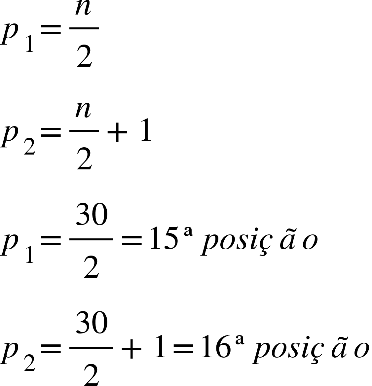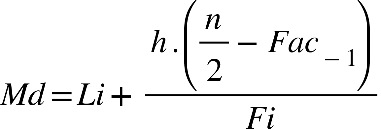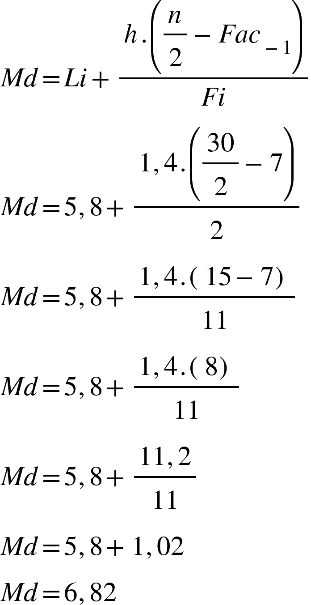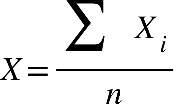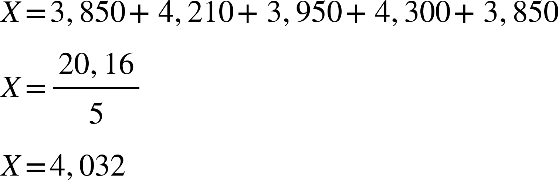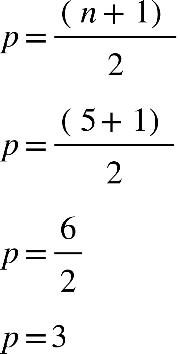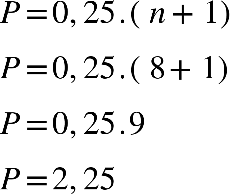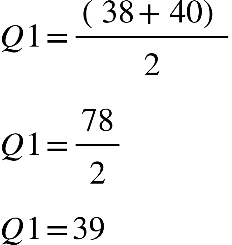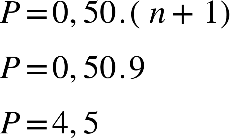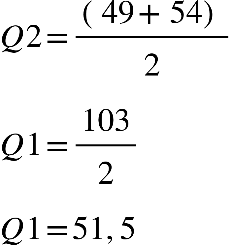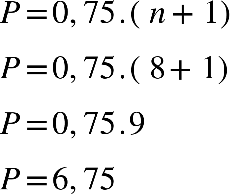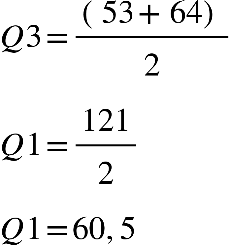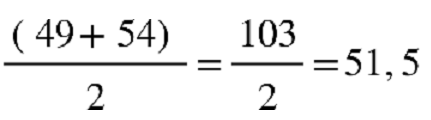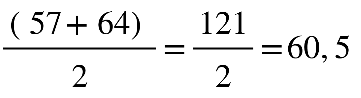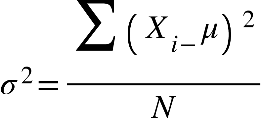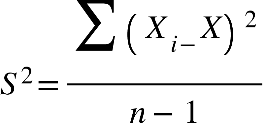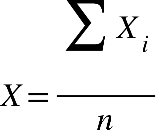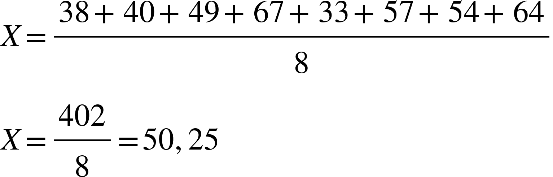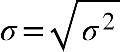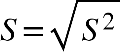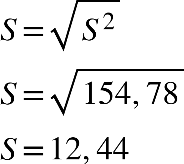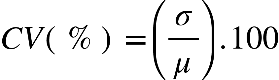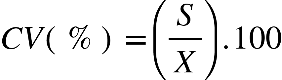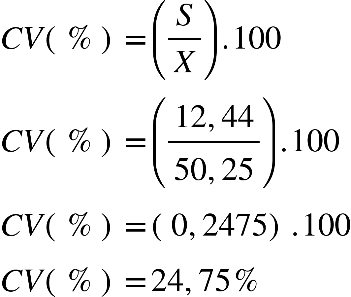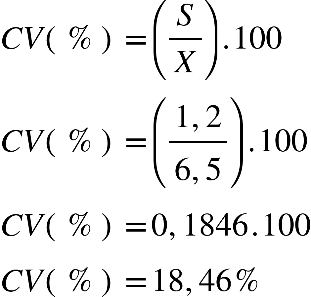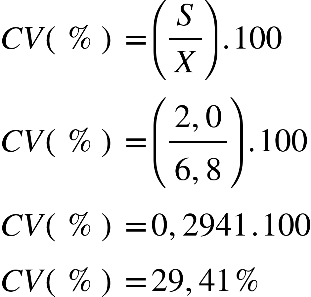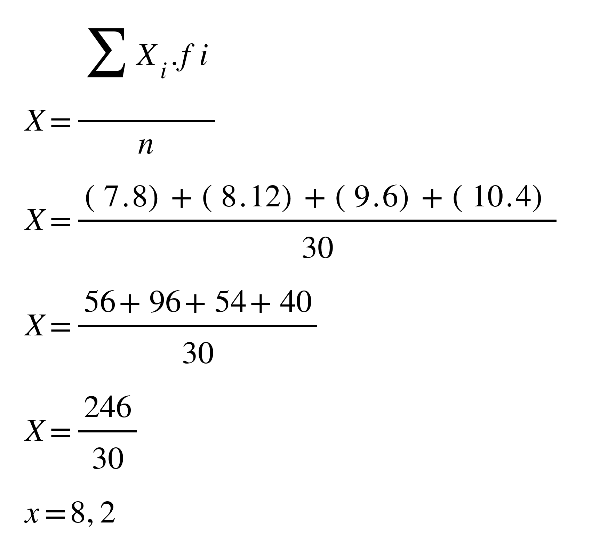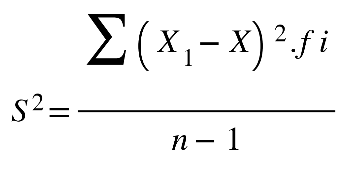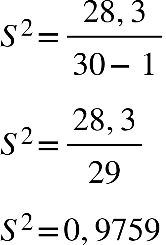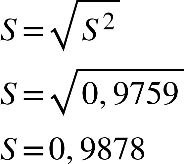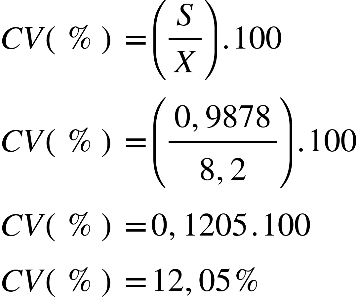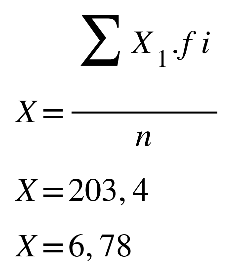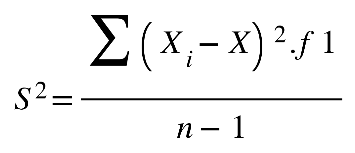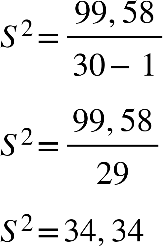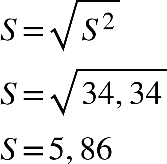Seja bem-vindo(a) ao tema Medidas De Posição E Dispersão! Este conteúdo será
fundamental para sua aprendizagem e para sua futura profissão. Por meio dela,
você terá oportunidade de entender como ocorre a análise dos dados oriundos de
uma pesquisa para que possa analisar situações quanto à frequência, à
incidência, às ocorrências, entre outras variáveis imprescindíveis para futura
atuação profissional. Você aprenderá a trabalhar com as medidas de posição,
separatrizes e variabilidade. Vamos lá?
Ao final deste tema de aprendizagem você será capaz de:
Entender como ocorre a análise dos dados oriundos de uma pesquisa para que
possa analisar situações quanto à frequência, às ocorrências, entre outras
variáveis imprescindíveis para futura atuação profissional.
Trabalhar com as medidas de posição, separatrizes e variabilidade.
Inicie sua jornada
Para que possamos dar início às nossas reflexões, vou nos transportar para a
primeira vez em que entrei em uma escola como professora da disciplina
Estatística. Naquele momento, eu tinha várias expectativas quanto à minha
atuação como docente. Aquele ambiente inspirava o conhecimento e o meu desejo de
ensinar.
No entanto, já em sala de aula, quando fiz a primeira
explicação/apresentação a respeito do que se tratava a disciplina de cálculo,
explicitei que, também, trabalhamos com a interpretação de dados e informações e
notei que isso foi uma surpresa para os estudantes daquela turma. Na aula
seguinte, fiz uma revisão de conteúdos de Matemática Básica, como fração,
multiplicação e expressão numérica, quando percebi a necessidade de mais aulas
relembrando este conteúdo com meus alunos.
Então, para ter um parâmetro de como estava a turma, fiz um teste, sem valer nota, mas
para ter um diagnóstico real de como poderia trabalhar.
Depois que fiz as correções dos
testes, calculei a média, a variância e o desvio padrão daquela turma e entendi que
havia muita
dispersão
, ou seja, parte da turma necessitava de uma atenção especial em cálculos básicos de
matemática, outra parte era intermediária, e outra parte tinha gabaritado o teste.
Com
essa turma heterogênea, era preciso cuidado e atenção, e isso me desafiava nesta
primeira experiência como professora.
Com este relato de minha história, desejo que você se atente aos conteúdos que
desbravaremos
e
compreender
juntos, que tratam de formas de se calcular as medidas de posição e dispersão e sobre
como perceber o quanto estas são importantes em nossa tomada de decisões.
Desenvolva seu potencial
Você percebeu que, como professora da disciplina Estatística, utilizei medidas de
dispersão para mensurar o conhecimento prévio da turma em Matemática Básica e, com base
nos resultados, fui traçando um planejamento pedagógico pensando na melhor maneira do
aprendizado da minha turma. Agora que entendemos que a estatística pode nos ajudar a
construir elementos para tomada de decisões, você, também, pode se apropriar destes
preceitos para a tomada de decisão em sua trajetória profissional e verá que essas
medidas ajudarão você a interpretar os resultados de que precisa em um conjunto de
dados.
Depois da leitura do artigo anterior, vamos pôr a mão na massa? Trabalharemos, agora,
com dados coletados em uma turma.
Sugiro que levante as notas dos seus colegas de
turma,
no primeiro, no segundo, no terceiro e no quarto módulo. Em seguida, determine a
média
para cada aluno(a), e analise o desempenho de sua turma
. Construa esta organização e
faça esta análise, e você já estará utilizando mais uma técnica apresentada pela
Bioestatística. Caso prefira, pode extrapolar este contexto de nosso exemplo para outras
áreas da sua vida, como com as contas de luz, água ou internet, ao longo do último ano.
Sendo assim, provoco você a fazer uma autoanálise sobre a sua aprendizagem de
tudo que foi explicado até agora, pois este processo mostrará que estas medidas
o ajudarão a interpretar os resultados de que precisa em um conjunto de dados. O
que você encontrou até aqui? Todas estas informações auxiliarão você? Diante
disso, convido você, acadêmico, a fazer suas anotações em um Diário de Bordo.
Construa uma tabela à mão com esses dados, a fim de anotar suas primeiras
impressões até o momento.
Neste momento, caro(a) estudante, estudaremos as medidas de posição, as
separatrizes e a dispersão. As medidas de tendência central possibilitam
representar um conjunto de dados com apenas um número (MARTINEZ, 2015). As
medidas de posição mais utilizadas e as que estudaremos são: a média, a moda e a
mediana.
Cada uma dessas medidas envolve fórmulas e aplicações diferentes, tornando a
Bioestatística ainda mais fascinante. “As medidas de tendência central só podem ser
calculadas para variáveis quantitativas”.
- PARENTI; SILVA; SILVEIRA, 2017, p. 116
A medida de posição
média
é a medida de tendência central mais conhecida e mais importante para um conjunto de
valores. Tenho certeza de que você já a utilizou no seu dia a dia, pois é bem simples de
ser calculada. Para o cálculo da média, basta somar todos os valores e, em seguida,
dividir pelo total de elementos. A média amostral é representada por um x com uma barra
em cima (
X
), e a média populacional pela letra grega
μ
(lê-se mi). Mesmo sendo representadas de maneira diferente, a forma de calcular é a
mesma. Para calcularmos a média, quando temos dados desagrupados, ou seja, sem estarem
em tabelas, podendo ser brutos ou em rol, é dada por:
= XIN
Em que: μ = Média Populacional Σ = Somatória Xi = Valor de cada elemento N =
Total da População
X= XIN
Em que: X = Média Amostral Σ = Somatória Xi = Valor de cada elemento n =
Total da Amostra
VOCÊ SABE
RESPONDER?
Como você pode observar, o cálculo da média é o mesmo tanto para a população quanto
para a amostra. Aposto que, neste momento, você está se questionando: mas como
funciona na prática? Sempre que não for mencionado que os dados são populacionais,
você pode considerar uma amostra, e isso acontece porque, geralmente, o trabalho com
amostras tem um custo e um tempo menor do que o trabalho com população. Você pode
observar que, na área das Ciências Biológicas e da Saúde, o uso de amostras é
recorrente.
Para compreender melhor o que eu desejo explicar para você aqui, o cálculo da média,
vejamos um exemplo. As idades (em anos) de oito pessoas que estão apresentadas, a
seguir:
38, 40, 49, 67, 33, 57, 54 e 64
Pensando Juntos
A média amostral, denotada por x (lê-se “xis barra”), é dada por:
X= XIN
= XIN= x1+x2+x3....xnn
Assim:
X=38+40+49+67+33+57+54+648
X=4028 + 50,25
Você pode observar que a média é apresentada na mesma unidade de medida da variável
analisada. E como interpretamos uma média de 50, 25 anos? Em primeiro lugar, tendo a
média como uma medida de tendência central, podemos afirmar que as idades das oito
pessoas de nossa amostra estão em torno de 50, 25 anos. A Figura 2 ajuda-nos a
visualizar a média e os dados apresentados.
Figura 2 - Apresentação dos dados e da média
Fonte: a autora.
Dessa forma, lembre-se de que a média é uma medida-resumo, isto é, ela visa sintetizar
em um único valor todas as nossas observações amostrais. Em outras palavras, afirmarmos
que a idade de 50, 25 anos é um valor que tem por intuito representar as idades de todas
as oito pessoas analisadas. No entanto você pode observar que a média é um resumo
incompleto de nosso conjunto de dados uma vez que ela não informa o tamanho da dispersão
de nossos dados a seu redor. Observe que, com a média de 50, 25 anos, temos pessoas com
33 anos, com 48 e com 67. Para explicar toda esta dispersão, existe o desvio padrão, que
discutiremos um pouco mais à frente.
Aprofundando
Supondo que, agora, temos uma amostra composta por oito mulheres, e a variável que nos
interessa é o número de filhos, para isso, temos:
1, 1, 1, 2, 2, 3, 3, e 4
A variável analisada é de natureza quantitativa discreta. A média amostral é:
X= XIN
X=1+1+1+2+2+3+3+48
A=178
X=2,125
X= XiN
Se o número de filhos é uma variável discreta, e não temos casas decimais, seria
possível ter uma média de 2,125 filhos? Ainda que a variável estudada não admita casas
decimais, a sua média pode sim ter casas decimais. Entretanto, neste exemplo
apresentado, basta uma casa decimal para a média, aí podemos utilizar a regra de
arredondamento e dizer que as famílias têm, em média, 2,1 filhos. Também podemos ter
interesse em calcular a média, em dados qualitativos apresentados em tabelas. Vejamos o
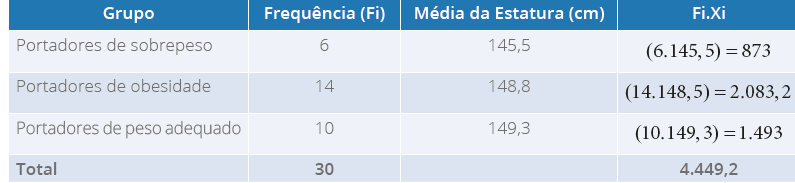
exemplo, na Tabela 1, a seguir:
Tabela 1 - Média das estaturas (em cm) de 30 adolescentes, conforme a classificação de
seus pesos
Fonte: a autora.
Para calcular a média neste caso, trabalharemos com a média ponderada, dada pela
equação:
X= XI.fin
Em que:
X
= média
Xi
= cada um dos valores (ou ponto médio)
n = número total de elementos (ou somatória das frequências)
Temos:
X= XI.fin
X=(6.145,5) + (14.148,8)+(10+149,3)30
X=873+2.083,32+1+49330
X= 4.449,3230
X=148,31
Em vez de calcular dessa maneira, para facilitar, você pode, dentro da sua tabela,
criar uma coluna complementar
e chamá-la de
xi.fi
, colocar os resultados em cada classe da multiplicação da frequência pelo valor da
variável e, depois, somar com o total na Tabela 2. Vejamos a seguir:
Tabela 2 - Média das estaturas (em cm) de 30 adolescentes, conforme a classificação de
seus pesos com coluna complementar
Fonte: a autora.
Zoom no Conhecimento
Agora, com o resultado da somatória das frequências pela variável, utilizamos a mesma
equação. Veja como fica:
X=X=x .fiin
X=4.449,3230
X = 148,31
Você, também, poderá encontrar situações, no seu cotidiano, já atuando como
profissional, em que você precisará calcular a média de idade de seus pacientes, ou,
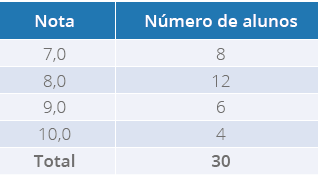
ainda, calcular médias de seus alunos utilizando os dados quantitativos. Vejamos um
exemplo hipotético em que analisaremos as notas de uma turma do curso de Biomedicina, na
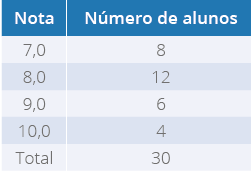
Tabela 3 a seguir:
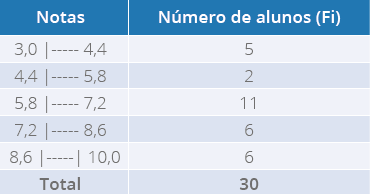
Tabela 3 - Notas de 30 alunos do Curso de Biomedicina
Fonte: o autor.
Para que o professor saiba a média em questão, ele realizará uma análise simples,
multiplicará a nota (variável que está sendo
estudada) pelo número de alunos, em seguida
dividirá pelo total da turma, que, neste caso, é de 30 alunos
. Utilizando a equação da
média, temos:
X=x .fiin
X=56+96+54+4030
X= 24630
X=8,2
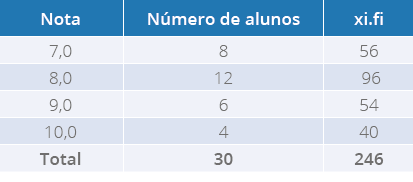
Outra opção para calcular, como vimos anteriormente, é criar a coluna complementar,
ficando, desta forma, na Tabela 4:
Tabela 4 - Notas de 30 alunos do Curso de Biomedicina
Fonte: a autora.
Pensando Juntos
Resolvendo a média, temos:
X=xi .fin
X=24630
X=8,2
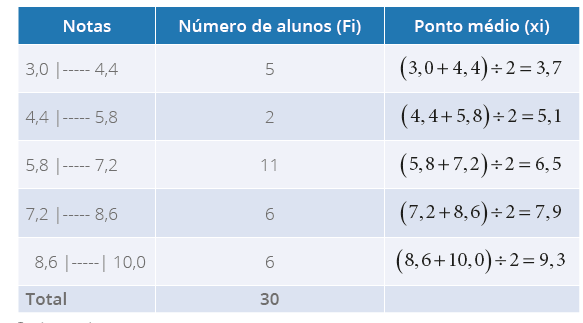
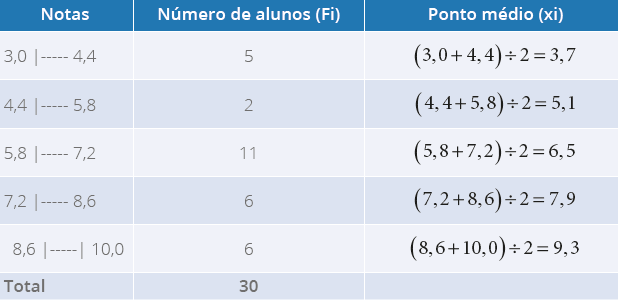
E se tivermos uma tabela de frequências com intervalo de classes, como calculamos a
média? Utilizaremos a mesma equação, mas precisaremos calcular o ponto médio. Vejamos um
exemplo: as notas dos alunos do curso de Biomedicina estão apresentadas na Tabela 5 a
seguir.
Tabela 5 - Distribuição de frequências referente às notas de alunos do Curso de
Biomedicina (com intervalo de classes)
Fonte: a autora.
Na Tabela 6, temos as notas dos alunos do curso para calcularmos a média. A fim de
facilitar, inseriremos uma coluna complementar, determinaremos o ponto médio
primeiro, utilizando a equação a seguir:
Xi=(Li+Ls)2
Em que:
Xi = Ponto médio
Li = Limite inferior do intervalo de classe (independente da notação)
Ls = Limite superior do intervalo de classe (independente da notação)
Agora, com a coluna complementar na tabela, determinaremos o ponto médio de cada classe,
na Tabela 6.
Tabela 6 - Distribuição de frequências referente às notas de alunos do Curso de
Biomedicina (com intervalo de classes)
Fonte: a autora.
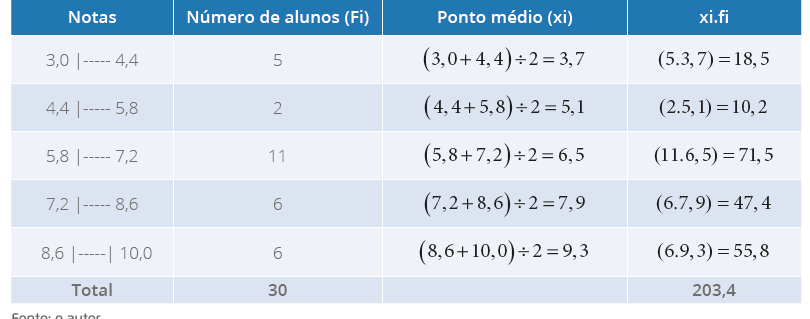
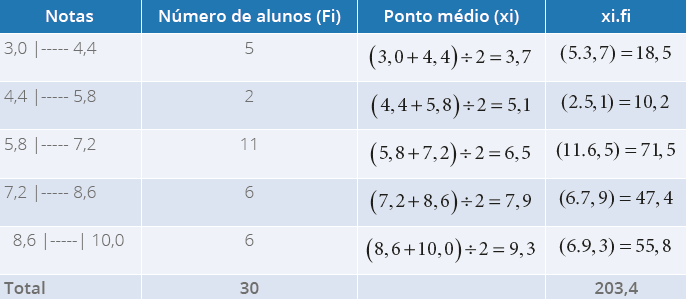
Agora que temos o ponto médio, basta inserir uma coluna complementar “xi.fi” e utilizar
a equação da média, que já trabalhamos, anteriormente. Reescrevendo, na Tabela 7, temos:
Tabela 7 - Distribuição de frequências referente às notas de alunos do Curso de
Biomedicina (com intervalo de classes)
Fonte: a autora.
Aprofundando
Determinando a média, temos:
X=xi .fin
X=203,430
X=6,78
A média da turma é 6,78, arredondando temos que a média da turma de Biomedicina é de
6,8.
Fonte: Parenti, Silva e Silveira (2017, p. 120).
A medida de tendência central mais conhecida e mais utilizada é a média, mas não
é sempre que ela é a mais apropriada para representar os dados, às vezes, a
mediana é mais adequada para representar um conjunto de dados. Isso ocorre
sempre que a variabilidade dos dados for alta, pois a média é afetada por
valores extremos, e a mediana não, ela apenas leva em consideração os valores
centrais.
Outra medida de posição importante é a
moda
. Você deve ter ouvido falar da expressão: “música que está na moda”, “roupa que está na
moda”, isso significa que tem muita frequência, muitas pessoas ouvindo a mesma música,
muitas pessoas usando mesmo estilo de roupa. Aqui na Bioestatística, esse conceito é bem
válido. Assim, para Martinez (2015), a moda é a observação que ocorre com maior
frequência no conjunto de dados, ou seja, o valor que mais se repete. Imagine que em uma
loja de calçados femininos foram vendidos 20 pares de sapatos em um único dia. Os pares
tinham estas numerações:
A numeração que aparece com mais frequência é o número 36. Significa que é uma
informação muito importante ao gerente da loja, pois indica que ele não pode
deixar de ter calçados 36 em seu estoque, porque vendem com mais frequência.
É importante não confundir moda com maioria. A moda é a observação mais
frequente, mas isso não implica, necessariamente, que a moda corresponde à
maioria das observações. (E. Z. Martines).Em outro exemplo, suponha que, em uma
turma de 1º ano de Nutrição, as idades dos 20 alunos (em anos completos) são:
Podemos descrever, adequadamente, as idades destes alunos dizendo que a idade mais
frequente, ou moda, é 18 anos. No entanto, em alguns casos, a moda pode não ser a medida
mais apropriada para caracterizar os dados. Como os valores a seguir são os níveis
séricos de triglicérides (em mg/dl) em uma amostra de sete pacientes:
189, 72, 109, 140, 140, 140, 135
A moda, neste exemplo, seria 140 mg/dl, sendo o valor mais frequente. Mas será
que a moda é a medida de posição que melhor caracteriza esses dados? Talvez a
média ou a mediana (que veremos a seguir) sejam mais úteis para esta finalidade.
Em algumas situações, a moda pode não ser única. Por exemplo, o tempo de
aleitamento materno (em meses) de 8 crianças usuárias de um serviço de saúde:
1, 2, 3, 3, 4, 6, 6
Neste exemplo, temos dois valores mais frequentes, 3 e 6 meses. Podemos dizer
que se trata de uma série bimodal, ou seja, dois valores de moda. Novamente, a
média ou a mediana podem ser mais úteis para descrever os dados desse exemplo.
Podemos não ter moda em um conjunto de dados, caso nenhum número se repita mais
vezes do que outro. Quando isso acontece, chamamos a distribuição de amodal. Se
tivermos mais do que duas modas, teremos uma distribuição multimodal (PARENTI;
SILVA; SILVEIRA, 2017).
Em alguns casos podemos ter interesse em saber a moda, mas os dados estão apresentados
em tabela, como fazer? Bem simples, basta olharmos os dados e a coluna frequência,
assim, vamos encontrar a classe modal, para então sabermos a moda. Observe os dados a
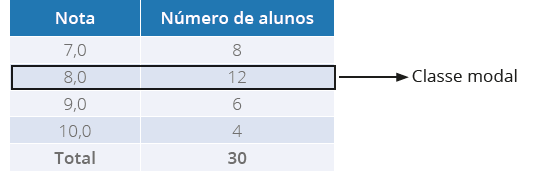
seguir, na Tabela 8.
Tabela 8 - Notas de alunos do Curso de Nutrição
Fonte: a autora
Para determinar a moda em tabelas, primeiramente, procuraremos a
classe modal
. Para isso, basta observar na coluna que tem a maior frequência. Em nosso exemplo,
a segunda classe tem doze alunos, que corresponde ao valor que aparece com mais
frequência, portanto, esta é a classe modal.
Em tabelas de frequências, também, podemos ter mais do que uma moda. Analise a seguir,
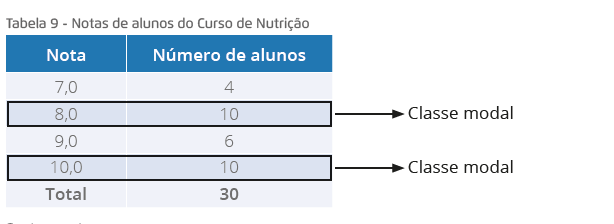
na Tabela 9.
Tabela 9 - Notas de alunos do Curso de Nutrição
Fonte: a autora.
Zoom no Conhecimento
Neste caso, as notas que aparecem com maior frequência são 8 e 10, temos uma série
bimodal, ou seja, com duas modas. E quando temos dados em tabelas de frequências com
intervalo de classes, como fica? Primeiro passo é localizar a classe modal, ou seja, a
classe que tem a maior frequência e, em seguida, utilizar a equação a seguir:
Mo=Li+h.(Fi-Fi-1)(Fi-Fi-1)+(Fi-Fi-1))
Em que:
Mo = Moda
Li = Limite da classe inferior (na classe modal)
h = Amplitude do intervalo (distância entre Li e Ls)
Fi = Frequência da classe
Fi−1
= Frequência da classe anterior
Fi+1
= Frequência da classe posterior
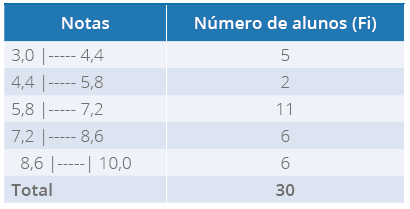
Para entender melhor, vejamos o exemplo na Tabela 10.
Tabela 10 - Distribuição de frequências referente às notas de alunos do Curso de
Nutrição (com intervalo de classes)
Fonte: a autora.
Aprofundando
Determine a moda. Para calcular a moda, procuraremos, na tabela, na coluna frequências,
a maior frequência para indicar a classe modal. Podemos observar que a moda está na
terceira classe da tabela, mas qual a moda? Determinaremos a seguir:
Encontramos que a nota que representa a moda é igual a 6,7; mas os dados não foram dados
em rol, com esta equação, encontramos o valor mais aproximado, observem que este valor
está dentro dos valores estabelecidos nos limites inferiores e superiores. Para Parenti,
Silva e Silveira (2017), a mediana é definida como sendo o valor central da distribuição
dos dados ordenados, e este divide a distribuição ao meio, sendo que metade dos valores
será menor ou igual à mediana, e a outra metade será maior ou igual à mediana. Até o
momento, quando calculávamos a média e a moda, fazíamos, diretamente, sem ter que
colocar os dados em rol, mas, para calcular a mediana, obrigatoriamente, devemos colocar
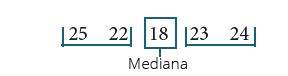
os dados em rol. Supondo que temos as idades de cinco alunos do curso de Nutrição, que
são dadas a seguir:
25 22 18 23 24
Encontre a mediana entre as idades dos alunos. Sabemos que a mediana divide o
conjunto de dados em duas partes iguais, não seria correto fazer simplesmente
assim:
Dessa forma está errada, pois a idade de 18 anos não é o que divide o conjunto
de dados em rol, pois, na mediana, estes dados devem ser ordenados, portanto:
Agora, temos a mediana, que é igual à idade de 23 anos.
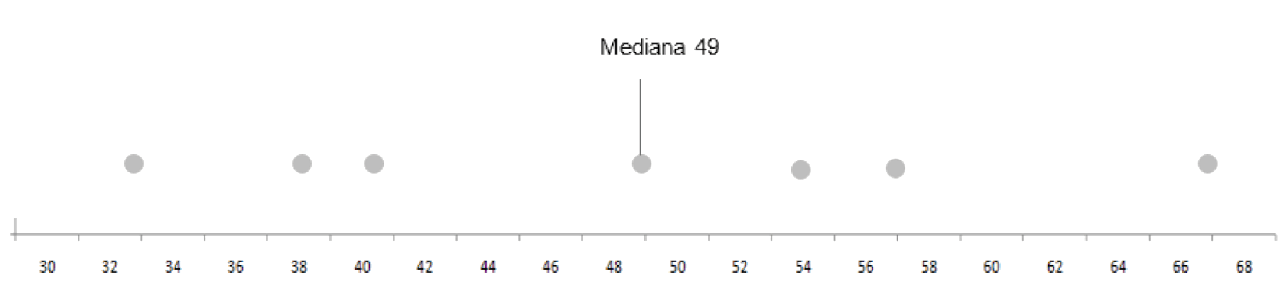
Vejamos outro exemplo: idades (em anos) de sete pessoas estão apresentadas a seguir:
38, 40, 49, 67, 33, 57, 54
Primeiro passo: colocar os dados em rol:
33, 38, 40, 49, 54, 57, 67
Encontrando a mediana, temos:
33, 38, 40,
49
,
54, 57, 67
Mediana igual a 49. Agora, representaremos, na Figura 3, para que você consiga analisar
os valores antes e depois da mediana.
Figura 3 - Representação na mediana / Fonte: o autor.
Zoom no Conhecimento
Se substituirmos a maior idade de 67 para 75 anos, o que aconteceria com a mediana? Seu
valor se modificaria? O
número do meio
continuaria sendo 49 anos. Esta é uma característica importante da mediana: ela não é
sensível a valores atípicos de nosso conjunto de dados, e entendemos por valor atípico
um número bastante grande ou pequeno em relação aos demais.
No cálculo da mediana, temos duas situações quando temos o conjunto de dados com números
pares e ímpares. Quando tivermos um número ímpar de elementos, a mediana será exatamente
o valor central. Também pode ser calculado pela equação a seguir:
Em que: P = posição do elemento que está à mediana n = número de elementos Por exemplo:
Notas de sete alunos do curso de Nutrição:
7,0 6,0 5,0 5,5 9,0 8,0 9,0
Colocando os dados em rol:
5,0 5,5 6,0 7,0 8,0 9,0 9,0
Utilizando a equação, temos:
O ‘p’ encontrado igual a 4, não é a mediana, mas sim o valor que ocupa a posição
mediana, ou seja, com os dados em rol, a mediana ocupa a
4ª posição
:
Podemos visualizar que a mediana é a nota 7,0, que ocupa a 4ª posição.
Quando tivermos um número par de elementos, a mediana será uma média simples entre os
elementos que ocupam a posição central o valor central. Pode ser calculado por:
Em que:
P = posição do elemento que está à mediana
n = número de elementos
Por exemplo: Notas de oito alunos do curso de Nutrição:
7,0 6,0 5,0 5,5 9,0 8,0 9,0 7,5
Colocando os dados em rol:
5,0 5,5 6,0 7,0 7,5 8,0 9,0 9,0
Utilizando a equação, temos:
Temos:
Agora, tiraremos uma média simples entre o elemento que está na quarta e na quinta
posição:
Muitas vezes, podemos ter o interesse em calcular a mediana em dados agrupados em
tabelas, para isso, precisaremos que nossa Tabela 11 tenha a coluna frequência
acumulada (FAC).
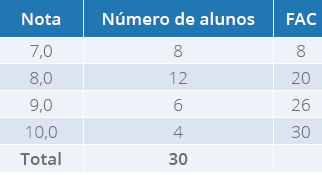
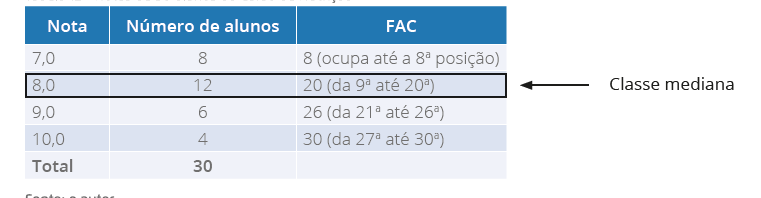
Tabela 11 - Notas de 30 alunos do Curso de Nutrição
Pensando Juntos
Para encontrar a mediana, como os dados já se encontram agrupados em uma tabela de
frequências, por meio da coluna frequência acumulada, vamos localizar o elemento que
ocupa a posição mediana, como nosso conjunto de dados é par, temos:
Agora com na coluna FAC, vamos localizar os elementos que ocupam a 15ª e a 16ª posição.
Veja na tabela 12, a seguir:
Tabela 12 - Notas de 30 alunos do Curso de Nutrição
Fonte: o autor.
Para este caso, o elemento que ocupa a 15ª e 16ª posição está na segunda classe é a nota
8,0, portanto, a nota mediana desta turma é 8,0. E
se tivesse uma nota em uma classe, e
outra na classe posterior? Simples, bastaria tirar a média simples entre as duas
notas.
Também podemos ter interesse em calcular a mediana
em uma distribuição de frequências
com intervalo de classes
. Para determinar a mediana, utilizamos a seguinte equação:
Em que:
Md = Mediana
Li = Limite da classe inferior (na classe mediana)
h = Amplitude do intervalo (distância entre Li e Ls)
n = número de elementos
Fi = Frequência da classe
Fac−1= Frequência acumulada da classe anterior
Agora, entenderá como calcular a mediana em dados agrupados em uma distribuição de
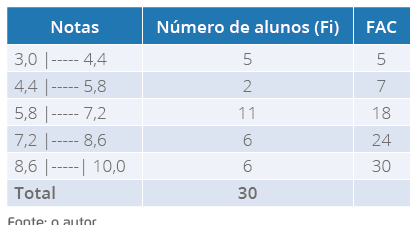
frequências com intervalo de classes. Observe na Tabela 13 a seguir.
Tabela 13 - Distribuição de frequências referente às notas de alunos do Curso de
Nutrição (com intervalo de classes)
Para resolvermos, temos primeiro que encontrar a posição mediana na coluna FAC. Como
nosso conjunto de dados é par, temos:
Aprofundando
Podemos observar, na tabela, que os dados estão na 3ª classe. Trabalharemos com estes
dados e substituiremos na equação da mediana.
Temos que a nota mediana da turma é igual a 6,8.
Compilaremos tudo que aprendemos em uma aplicação: Em uma maternidade, a enfermeira está
anotando os pesos dos recém-nascidos na manhã de um domingo, quando cinco bebês
nasceram. Os dados são (em kg):
3,850 4,210 3,950 4,300 3,850
Vamos calcular as medidas de tendência central para estes dados:
Em média, os bebês daquela manhã de domingo pesavam 4,032 kg.
valor que mais se repete, portanto é 3,850 kg. Assim: O valor mais frequente
para o peso dos recém-nascidos naquela maternidade é de 3,850 kg.
colocar os dados em rol:
3,850 3,850 3,950 4,210 4,300
A mediana será o terceiro elemento do conjunto de dados ordenados. Portanto,
3,950. Assim: metade das crianças nascidas na maternidade pesava menos de
3,950kg, e a outra metade pesava mais do que 3,950 kg.
A medida de tendência central mais conhecida e mais utilizada é a média, mas não é
sempre que ela é a mais apropriada para representar os dados, às vezes, a mediana é
mais adequada para representar um conjunto de dados. Isso ocorre sempre que a
variabilidade dos dados for alta, pois a média é afetada por valores extremos, e a
mediana não, ela, apenas, leva em consideração os valores centrais.
- Parenti, Silva e Silveira (2017).
Figura 4 - Representação dos quartis / Fonte: o autor.
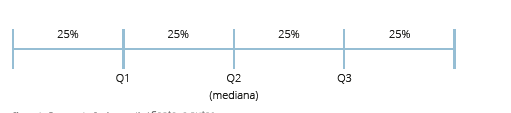
Outras medidas que você pode utilizar são as separatrizes que dividirão as
séries em partes iguais, e as principais são: mediana (que já estudamos),
quartis, decis e percentis. Os quartis dividem uma série de dados em quatro
partes iguais, assim, temos: 1º quartil, 2º quartil e 3º quartil (CRESPO, 2009).
Esta representação encontra-se na Figura 4, a seguir.
Assim, como pode observar na Figura 5, segundo Crespo (2009) temos os três
quartis:
Figura 5 - Três Quartis / Fonte: Crespo (2009).
Para calcular, é bem simples, basta organizar a série de dados em rol, e utilizar as
equações a seguir:
1º Quartil (Q1): P=0,25.(n+1)
2º Quartil (Q2): P=0,50(n+1)
3º Quartil (Q3): P=0,75(n+1)
Por exemplo, calcularemos Q1, Q2 e Q3 para um grupo que tem idades de oito
pessoas:
38, 40, 49, 67, 33, 57, 54 e 64
Primeiro passo: colocar os dados em rol.
33, 38, 40, 49, 54, 57, 64, 67
Neste caso, o Q1, será uma média simples entre 2º e 3º elemento:
Neste caso, o Q2, será uma média simples entre 4º e 5º elemento:
Neste caso, o Q3 será uma média simples entre 6º e 7º elemento:
Zoom no Conhecimento
Outra medida separatriz é o decil. Este divide uma série em dez partes iguais (CRESPO,
2009). As equações para calcular estão apresentadas a seguir:
1º Decil (D1): P=0,10 (n+1)
2º Decil (Q2): P=0,20 (n+1)
3º Decil (Q3): P=0,30 (n+1)
4º Decil (Q4): P=0,40 (n+1)
5º Decil (Q5): P=0,50 (n+1)
6º Decil (Q6): P=0,60 (n+1)
7º Decil (Q7): P=0,70 (n+1)
8º Decil (Q8): P=0,80 (n+1)
9º Decil (Q9): P=0,90 (n+1)
Por exemplo: calcular D3 e D4 e para um grupo que tem idades de oito pessoas:
38, 40, 49, 67, 33, 57, 54 e 64
Primeiro passo: colocar os dados em rol.
33, 38, 40, 49, 54, 57, 64, 67
O 4º decil será o elemento que ocupa a posição 3,6, arredondando para 4º, assim, nosso
quarto decil é igual a 49. Como percentil, temos como definição: os noventa e nove
valores que separarão uma série de dados em cem partes iguais (CRESPO, 2009). Pode ser
calculado por meio das equações a seguir:
Por exemplo: calcular P50 e P75 e para um grupo que tem idades de oito pessoas:
38, 40, 49, 67, 33, 57, 54 e 64
Primeiro passo: colocar os dados em rol.
33, 38, 40, 49, 54, 57, 64, 67
50º Percentil (P50): P=0,50.(n+1)
P=0,50.( n+1)
P=0,50.( n+1)
P= 0,50.( 8+1)
P= 0,50.(9)
P=4,5
Portanto, o P50 é igual ao elemento que está na 4,5ª posição, portanto uma média simples
entre 49 e 54:
Portanto, o P75 é igual ao elemento que está na 6,75ª posição, portanto uma média
simples entre 57 e 64:
Além das medidas separatrizes, temos as medidas de dispersão, que são importantes no
processo decisório. Com as medidas de dispersão e variabilidade, é possível entender
a homogeneidade ou a heterogeneidade dos dados (PARENTI; SILVA; SILVEIRA, 2017). As
medidas de dispersão são avaliadas em conjunto com as medidas de tendência central.
Com as medidas de dispersão, podemos analisar como os dados estão se comportando em
torno da média, da moda e da mediana. É
importante salientar que, apesar de dois
conjuntos de dados terem a mesma média, eles podem não ter o mesmo comportamento
e a
mesma variabilidade, para isso, é importante analisar os dados e fazer estas
comparações para entender o comportamento dos dados.
Não podemos interpretar as medidas de tendência central isoladamente. Para verificar
se as medidas de variabilidade representam bem os dados, precisamos calcular e
analisar as medi- das de variabilidade.
- E. Z. Martinez
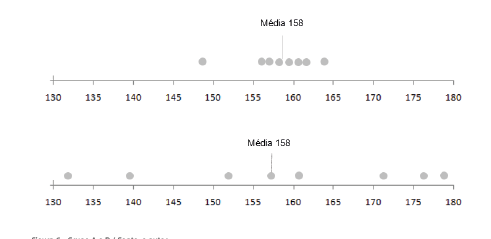
Vejamos outro exemplo. Seja a estatura (em cm) observada em duas amostras de
adolescentes saudáveis, denotaremos essas amostras por A e B.
As estaturas dos adolescentes da amostra A são: 149 156 157 158 159 160 161 164
As estaturas dos adolescentes da amostra B são: 132 138 152 157 160 171 176 178
Ao calcular a média da amostra A e B, ambas são 158 cm. As medianas de ambas as
amostras (A e B) são iguais a 158,5. Assim, as amostras A e B possuem médias e
medianas idênticas. Mas o fato de as amostras A e B possuírem medidas de posição
iguais (média e mediana) permite-nos afirmar que adolescentes das amostras A e B
são semelhantes em relação à estatura? Vejamos a Figura 6 que apresenta o grupo
A e B.
Figura 6 - Grupo A e B / Fonte: o autor.
Na Figura 6, podemos observar as dispersões destas observações. Percebemos que, embora
as medidas de locação sejam iguais, as amostras têm diferença quanto à dispersão dos
dados. Na amostra A, as observações possuem uma dispersão menor em relação à média de
158 cm, já na amostra B, as observações encontram-se mais dispersas em relação a mesma
média amostral.
Se dissermos somente que a média das estaturas é de
158 cm, estaremos
dizendo que nossas observações amostrais flutuam em torno de 158 cm, mas não temos
informação do tamanho da dispersão dos dados em relação a essa média.
Com isso, podemos evidenciar que as medidas de posição (média, moda e mediana),
muitas vezes, dão um resumo incompleto do comportamento de nossos dados uma vez
que elas não nos dizem nada a respeito da dispersão dos dados. Assim, torna-se
tão importante a apresentação de medidas de variabilidade dos dados.
Vamos conhecer estas medidas de dispersão? Iniciamos pela Amplitude total, de
acordo com Martinez (2015), a amplitude é dada pela distância entre o maior
valor do conjunto de dados pelo menor valor do conjunto de dados. Assim, a
amplitude total só leva em consideração os extremos, não chega a comparar os
valores da distribuição com a média destes dados.
Zoom no Conhecimento
É calculada pela equação a seguir:
AT=Xmáx-Xmín
Em que:
AT = Amplitude total
Xmáx = Maior valor do conjunto de dados
Xmín = Menor valor do conjunto de dados
Por exemplo, temos oito pessoas cujas idades são apresentadas a seguir:
38, 40, 49, 67, 33, 57, 54 e 64
A pessoa mais velha tem 64 anos, e a mais nova, 33 anos. A amplitude vamostral é,
portanto:
AT=Xmáx-Xmín
AT = 64-33
AT=31
Podemos interpretar a AT como sendo a maior diferença que é possível encontrar
entre duas quaisquer observações de nossa amostra (MARTINEZ, 2015). Assim, a AT
deve ser utilizada com certa cautela para descrever a amplitude de nossos dados,
dado que ela é, fortemente, influenciada por valores atípicos, sendo não
recomendado seu uso
sozinha
para interpretação de variabilidade dos dados.
Outra medida de dispersão é a variância, calculada com todos os dados da série e
comparada cada um deles com a média. A variância mede a distância de cada um dos
valores em relação à média (MARTINEZ, 2015). Por uma questão matemática,
precisamos elevar ao quadrado cada uma dessas distâncias para podermos eliminar
o sinal. Depois disso, fazemos a média dos quadrados destas diferenças.
Lembre-se de que não teremos variância negativa, certo?
Caso a variância esteja sendo calculada para os dados de uma população, representaremos
este valor pela letra grega sigma ao quadrado σ2. Em vez de dividirmos por n-1,
dividimos o somatório por N, sendo que n é o número de elementos da amostra, e N é o
número de elementos da população. A variância populacional e amostral é calculada por:
Em que:
s2 = Variância Populacional
Xi = Cada valor/elemento
μ = média populacional
N = Número de elementos
Σ = Somatória
Em que:
S2 = Variância Amostral
Xi = Cada valor/elemento
X = média amostral
n −1= Número de elementos (menos 1)
Σ = Somatória
Como você pode observar, a única diferença na prática do cálculo da variância
populacional e amostral é que, na variância amostral, tiraremos um elemento na hora de
fazer a divisão. É válido lembrar que, na maioria das situações, utilizamos amostras,
por questão de custo, da forma de coletar, entre outros. Entenderá na prática.
Temos oito pessoas cujas idades são apresentadas a seguir:
38, 40, 49, 67, 33, 57, 54 e 64
Determinaremos a variância amostral. Lembrando que precisaremos da média para calcular a
variância.
Agora que relembramos a média, calcularemos a variância amostral,
substituindo os valores na equação:
Aprofundando
Como você pode observar, a variância calcula a soma dos quadrados das distâncias em
relação à média. Como elevamos todos os termos ao quadrado, a nossa unidade de medida
também fica alterada. Se, por exemplo, estivermos calculando a variância da altura de
alunos do curso de Ciências Biológicas, e a medida está em cm, todos os elementos
determinados estarão em cm2. Sendo assim, nós não podemos comparar a variância,
diretamente, com a média ou com outras medidas, pois precisaremos extrair a raiz da
variância, e a isso denominamos desvio padrão.
Como desvio padrão é a raiz quadrada da variância, calculamos pela equação a seguir:
Em que:
s = desvio padrão Populacional
s2 = variância populacional
Desvio padrão amostral
Em que:
S = desvio padrão amostral
S2= variância amostral
Determinando o desvio padrão, do exercício anterior, temos:
A variabilidade entre as idades do grupo analisado é de 12,44 anos.
Se quisermos comparar a variabilidade de duas ou mais amostras (ou populações), para
Parenti, Silva e Silveira (2017), podemos fazer esta comparação somente com o uso do
desvio padrão. Mas podemos comparar utilizando o coeficiente de variação, que nos dará
em percentual a variabilidade dos dados, determinado por:
Em que:
CV% = Coeficiente de variação
σ = desvio padrão populacional
μ = média populacional
Coeficiente de variação (amostral):
CV% = Coeficiente de variação
S = desvio padrão amostral
X = média amostral
Determinando o CV% amostral do exercício anterior, temos:
Zoom no Conhecimento
Quando utilizado o coeficiente de variação, sempre que quisermos descobrir qual grupo de
dados é mais homogêneo, ou seja, que tem menor variabilidade em torno da média,
optaremos pelo grupo que tiver o menor percentual do coeficiente de variação, pois, se o
CV(%) for muito elevado, pode ser que a média não seja melhor medida para representar os
dados, devido à variabilidade em torno dela (MARTINEZ, 2015).
Supondo que, no curso de Ciências Biológicas, a média da turma A, na disciplina de
Bioestatística, é 6,5, e o desvio padrão 1,2, e, na turma B, a média é de 6,8, e o
desvio padrão é de 2,0, qual das duas turmas tem menor variabilidade dos dados?
Determine, por meio do Coeficiente de variação. Para resolução, basta observar que já
temos a média calculada e o desvio padrão também, é, simplesmente, calcularmos o CV (%).
Para turma A, temos:
Já para turma B, temos:
Portanto, a turma que tem uma variabilidade menor é a turma A, em que o CV foi de
18,46%.
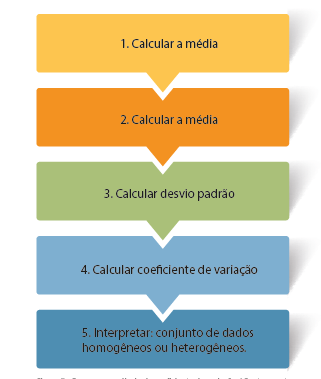
Observe um resumo dos cinco passos para o Cálculo do Coeficiente de Variação.
Seguindo este passo a passo, temos o exemplo na Figura 7.
Figura 7 - Passos para cálculo do coeficiente de variação / Fonte: o autor.
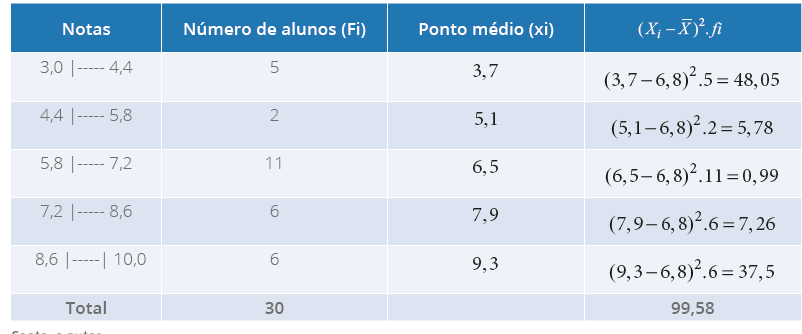
Também podemos ter interesse em calcular: variância, desvio padrão, em dados que
aparecem em tabelas de frequências. Vejamos a seguir:
a) Cálculo das medidas de variabilidade em tabelas de frequências sem intervalo de
classes:
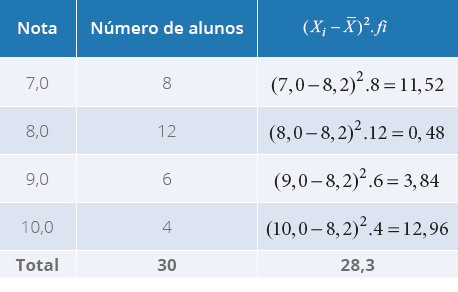
as notas de 30 alunos do curso de Ciências Biológicas estão apresentadas na distribuição
de frequências a seguir:
Tabela 14 - Notas de 30 alunos do Curso de Ciências Biológicas
Fonte: o autor.
Aprofundando
O primeiro passo é sabermos a média, antes de calcular a variância amostral, para isso,
temos:
Agora que já sabemos a média, utilizaremos a equação a seguir:
Em que:
S2 = Variância Amostral
Xi = Cada valor/elemento
X = média amostral
n −1= Número de elementos (menos 1)
Σ = Somatória
Fi = frequência
Para facilitar nosso cálculo, abriremos uma coluna a mais em nossa distribuição de
frequência e inseriremos o numerador da equação da variância, conforme Tabela 15.
Tabela 15 - Notas de 30 alunos do Curso de Ciências Biológicas
Com os dados da somatória de ().
XX
fi
i
− 2, substituiremos na equação:
Agora que temos o resultado e substituindo o valor “28,3” encontrado na tabela, por meio
da coluna ().
XX
fi
i
− 2, temos:
Com o resultado da variância, conseguimos calcular o desvio padrão:
Podemos calcular o coeficiente de variação:
b) Cálculo das medidas de variabilidade em tabelas de frequências com intervalo de
classes:
As notas dos alunos de uma turma de Ciências Biológicas estão apresentadas na tabela a
seguir. Determine o CV.
Tabela 16 - Distribuição de frequências referente às notas de alunos do Curso de
Ciências Biológicas (com intervalo de classes)
Para isso, calcularemos na sequência:
Média amostral.
Variância amostral.
Desvio padrão amoral.
Coeficiente de variação.
Iniciaremos calculando a variância amostral. Assim, para o seu cálculo, a equação
utilizada para tabelas sem ou com intervalo de classes, é a mesma que acabamos de ver.
A
única diferença na prática é que: em uma distribuição de frequências com intervalo de
classes, nosso “Xi” será o ponto médio, e não simplesmente a variável estudada.
Lembre-se de que o ponto médio é fundamental para se calcular a média desse tipo de
distribuição de frequência.
Calculando a média amostral, temos:
Tabela 17 - Distribuição de frequências referente às notas de alunos do Curso de
Ciências Biológicas (com intervalo de classes)
Fonte: o autor.
Zoom no Conhecimento
Determinando a média, temos:
Arredondando, temos que a média da turma de Ciências Biológicas é de 6,8. Com o
resultado da média, vamos reescrever a tabela, para determinar a variância amostral,
para utilizar a equação a seguir:
Com a tabela ajustada, temos:
Tabela 18 - Distribuição de frequências referente às notas de alunos do curso de
Ciências Biológicas (com intervalo de classes)
Agora que calculamos a variância na tabela, é só substituir na equação:
Substituindo, na equação, pelos valores encontrados na Tabela 18, temos:
Logo após, determinaremos o desvio padrão:
Agora, com o desvio padrão, podemos calcular o CV(%):
Eu indico
Você sabia que um profissional da área de Biológicas ou da Saúde, também, pode ser um pesquisador? Pode pesquisar na área de meio ambiente, saúde, laboratorial, e é vasto o campo para esse profissional. Nossa Roda de Conversa trará como as medidas de posição e dispersão podem ajudar na interpretação de resultados em uma pesquisa. O vídeo estará disponível no seu ambiente virtual de aprendizagem.
No caso desta turma, com um coeficiente de variação de 86,71%, podemos concluir que
há uma dispersão muito grande das notas, e que a média pode não ser a medida ideal
para interpretar estes dados. Mas quando olhamos para os dados com mais cautela,
temos alunos que tiraram 3,0; 4,0; 5,0; 10. E o que isso quer dizer? Como conclusão,
temos que essa turma apresenta uma grande dispersão no quesito nota, porque o
resultado encontrado de 86,71% é superior a 50%. Isso quer dizer que existem alunos
que estão indo bem na disciplina, mas também existem alunos que não estão
aprendendo.
VOCÊ SABE
RESPONDER?
Assim, podemos refletir: com tanta dispersão, o que posso melhorar para que todos
tenham um aprendizado? As medidas de dispersão podem ajudar neste caminho. Agora que
temos os dados em mãos, podemos trabalhar para melhorar a maneira de ensinar nesta
turma.
Eu indico
Você sabia que a área da Biologia, além das questões ambientais, educacionais, engloba a área da saúde? Assim, você pode consultar periódicos com aplicação da Bioestatística, e convido a fazer as leituras dos artigos a seguir. Clique aqui para ler.
Novos desafios
Estudante, finalizamos compreendendo o processo pelo qual as medidas de posição, as
separatrizes e a dispersão podem ajudar a trabalhar melhor com os dados e auxiliar no
processo decisório. Como educadores e profissionais da saúde, temos que ter a
consciência da importância da Bioestatística, pois, como vimos, ela traz a preocupação
de entender como os dados podem trazer indicativos para um professor em sala de aula.
A partir das medidas de posição, você conseguirá trabalhar com seus dados, entendendo o
com portamento dos mesmos, e com as medidas de dispersão, como você percebeu,
conseguimos entender se a média é representativa, ou não, para o conjunto de dados.
Dentro da Bioestatística, você poderá observar os resultados de sua pesquisa sendo uma
ferramenta, essencial para a tomada de decisões, e que estará presente no seu futuro
profissional.
Espero que tenha tirado máximo proveito desse conteúdo.
REFERÊNCIAS
BASTOS, J. L. D.; DUQUIA, R. P. Medidas de dispersão: os valores estão
próximos entre si ou variam muito? Notas de Epidemiologia e Estatística.
Scientia Medica, Porto Alegre, v. 17, n. 1, p. 40-44, jan./ mar., 2007.
Disponível em:
https://webcache.googleusercontent.com/search?q=cache:pxyqpAQBmGY
J:https://revistaseletronicas.pucrs.br/ojs/index.php/scientiamedica/article/download/1650/1845/+&cd=2&hl=pt-BR&ct=clnk≷=br.
Acesso em: 17 maio 2021.
CRESPO, A. A. Estatística. 19. ed. São Paulo: Atlas, 2009.
INEP. Sinopse Estatística da Educação Básica 2019. Brasília: Inep, 2020.
Disponível em: http://portal.
inep.gov.br/sinopses-estatisticas-da-educacao-basica. Acesso em: 18 maio
2021.
MARTINEZ, E. Z. Bioestatística para os cursos de graduação da área da saúde.
São Paulo: Blücher, 2015. Disponível em:
https://pt.slideshare.net/bookcadastro/9788521209027. Acesso em: 18 maio
2021.
PARENTI, T. M. S.; SILVA, J. S. F. da.; SILVEIRA, J. Bioestatística. Porto
Alegre: SAGAH, 2017.
RODRIGUES, C. F. S.; LIMA, F. J. C. de.; BARBOSA, F. T. Importância do uso
adequado da estatística básica nas pesquisas clínicas. Artigo de Revisão.
Revista Brasileira de Anestesiologia, n. 67 v. 6, p. 619-625, 2017.
Disponível em:
https://www.scielo.br/pdf/rba/v67n6/pt_0034-7094-rba-67-06-0619. pdf. Acesso
em: 18 maio 2021.
















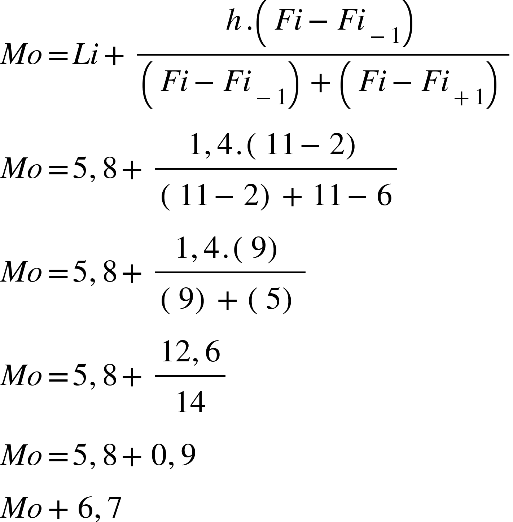
.png)